- Mateusz Oracz
- 14 maja 2026
Matura z informatyki 2026 przechodzi do historii. Arkusz jest już oficjalnie dostępny na stronie CKE, zatem zapraszam na wspólną analizę tegorocznych zadań. Spojrzymy na to, co przewidywaliśmy przed maturą, a co okazało się niespodzianką, gdzie były klasyczne motywy z poprzednich lat, a gdzie autorzy postanowili lekko namieszać.
Ten artykuł nie zastąpi pełnej lekcji – nie wchodzę w każdy najmniejszy szczegół. Skupiam się tu na całościowej ocenie arkusza, omawiam podejścia do rozwiązań oraz wyniki.
A więc zaczynamy. Zobaczmy, co czekało na maturzystów 14 maja 2026 roku.
Zadanie 1: Rekurencja – Matura z Informatyki 2026

Mamy tutaj klasyczny przykład rekurencji, w której wartość funkcji zależy od parzystości jednego z argumentów. Jak zaraz zobaczymy – mimo pozornej złożoności – realizuje ona tak naprawdę całkiem proste działanie.
Zerknijmy jeszcze raz na definicję funkcji. Gdy n jest parzyste, m się podwaja, a n zmniejsza o połowę. Gdy n jest nieparzyste, m pozostaje bez zmian, natomiast n jest zmniejszane o 1, a następnie dzielone przez 2.
Nie wiesz jeszcze, o co chodzi i jak działa ta funkcja A? Nie ma problemu – dopiero realizując poszczególne podpunkty, postaramy się to razem zrozumieć. Na tym etapie podchodzimy do tego czysto matematycznie, jak do zwykłego wyrażenia z zadania.
Zadanie 1.1: Analiza wywołań rekurencyjnych funkcji A

Mamy do uzupełnienia tabelę z kolumnami: m, n, liczba wywołań rekurencyjnych oraz same wywołania rekurencyjne funkcji A.
Jest to typowe zadanie maturalne – tylko zamiast pseudokodu mamy funkcję opisaną rekurencyjnym wzorem z warunkami. Możesz uderzyć w problem na dwa sposoby:
- Program lub arkusz — przepisujemy definicję A do dowolnego języka dozwolonego przy maturze i dla kolejnych par (m, n) uruchamiamy kod oraz odczytujemy wynik albo łańcuch wywołań. Szybkie uzupełnienie tabeli przy mniejszym wysiłku obliczeniowym.
- Ręczne prowadzenie wywołań — zamiast maszyny wywołujemy kolejne A(…,…) na kartce przy definicji z arkusza. Trwa dłużej, ale to właśnie ta droga pokazuje, dlaczego funkcja się tak zachowuje.
A to ma znaczenie, bo bardzo często w zadaniu 1.2 lub 1.3 pojawiają się pytania sprawdzające właśnie to zrozumienie działania funkcji.
Może przejdźmy więc drogą zrozumienia – krok po kroku, zamiast od razu przerzucać wszystko do programu.
Analiza przykładu z zadania
Przechodzimy więc do obliczeń. Zaczynamy od analizy przykładu, który jest już uzupełniony, żeby zrozumieć cały mechanizm.
Zaczynamy od m = 3 oraz n = 9.
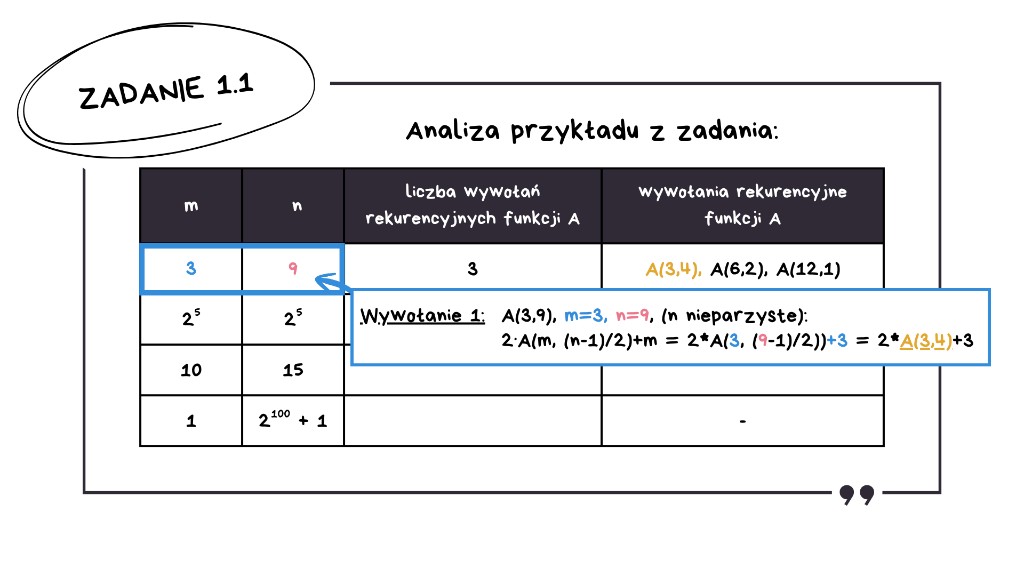
Zerkając na definicję funkcji: n jest równe 9, czyli nieparzyste, zatem podstawiamy do wzoru dla n nieparzystych. Wynikiem jest 2 · A(m, (n-1)/2) + m, czyli 2 · A(3, 4) + 3. To jest nasze pierwsze wywołanie rekurencyjne.
Nie wiemy jeszcze, jaką wartość ma wywołanie funkcji A z parametrami 3 i 4, zatem przechodzimy do kolejnego wywołania.

Tym razem n jest równe 4, czyli parzyste – podstawiamy do wzoru i wynikiem jest wywołanie A(6, 2).
Nadal nie znamy wyniku, więc przechodzimy do trzeciego wywołania.
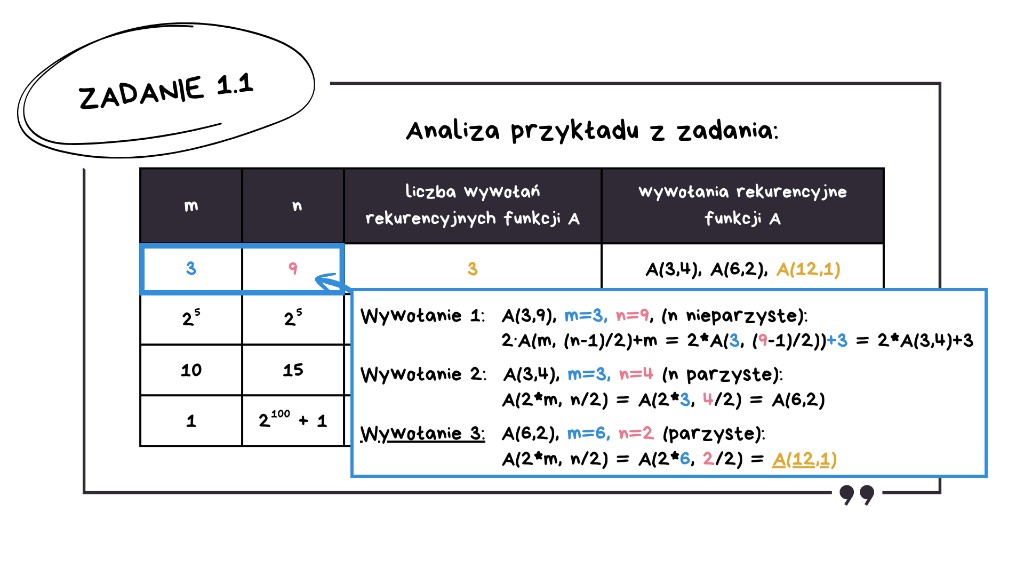
Znów n jest parzyste – i otrzymujemy wywołanie funkcji A(12, 1). Tym razem n jest równe 1, zatem patrząc na definicję funkcji: rekurencja się kończy, ponieważ dla n = 1 wynikiem jest po prostu m, czyli 12.
Teraz moglibyśmy wrócić do góry i obliczyć wartość początkowego A(3, 9) – natomiast w tabelce wymagają od nas tylko wypisania wywołań, więc jak widzimy, nasze wywołania się zgadzają.
A zamiast obliczeń wyniku, zerknijmy do treści zadania. W tych obliczeniach, które pominęliśmy, mamy dokładnie to, co obliczyliśmy, czyli 2 · A(12, 1) + 3, czyli 2 · 12 + 3, zatem wynikiem jest 27.
Kolejne wiersze tabeli
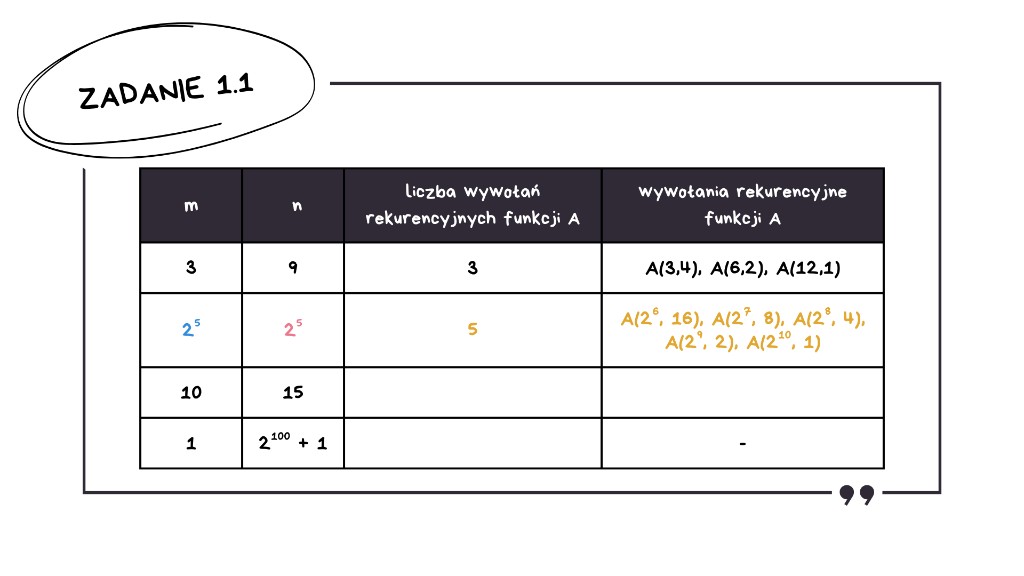
Przechodzimy do kolejnego wiersza tabeli, czyli do wartości m = 25 oraz n = 25. Tutaj w analogiczny sposób podstawiamy do wzoru i uzupełniamy tabelę.
A kolejno dla m = 10 i n = 15 – również podstawiamy do wzoru.
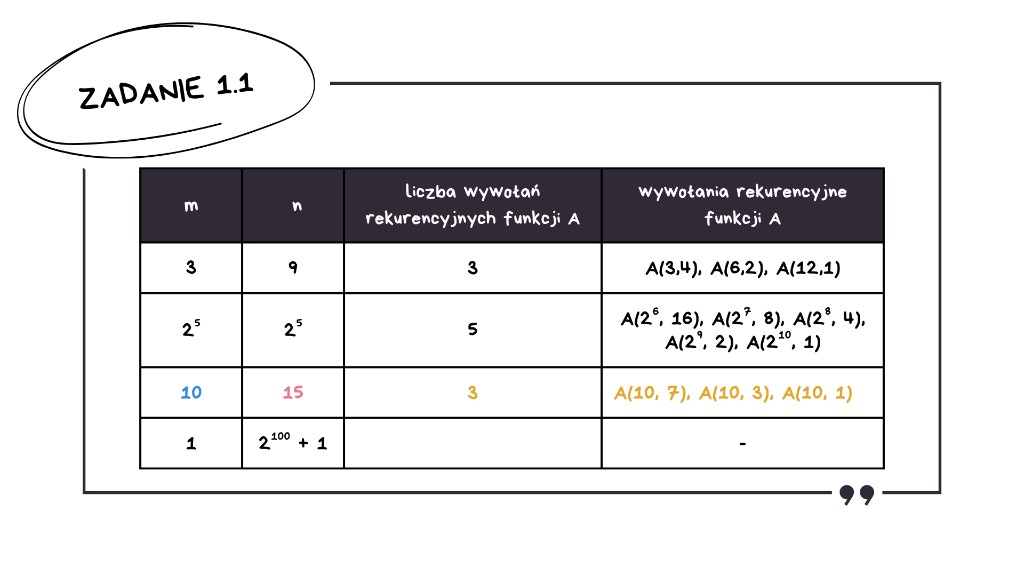
Sprytne podejście do dużych wartości
Problem może się pojawić przy ostatnim wierszu, dla n = 2100 + 1. Wywołań będzie tutaj sporo, więc trzeba podejść do tego sprytniej.
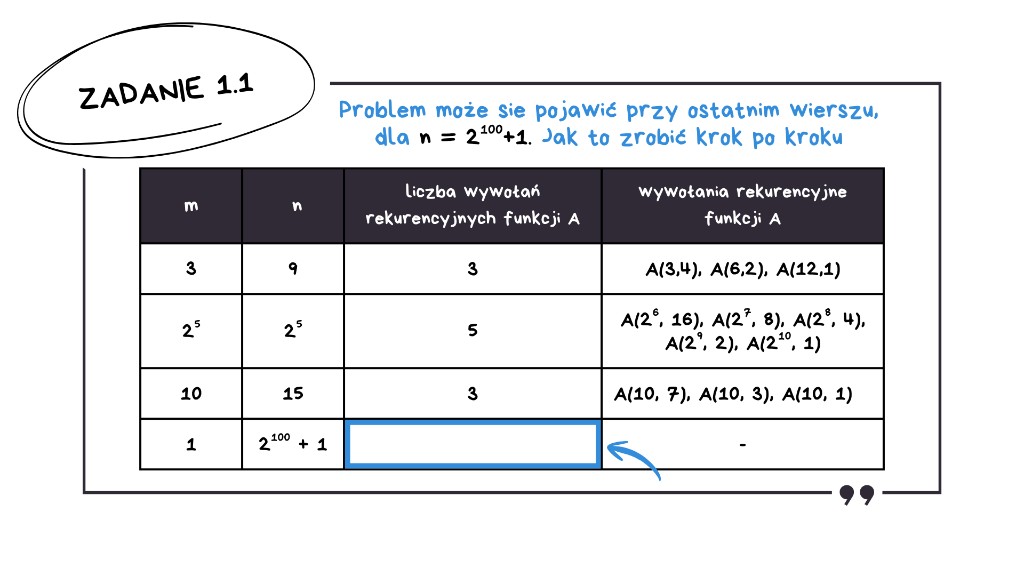

W pierwszym kroku n jest nieparzyste, ponieważ 2100 + 1 jest liczbą nieparzystą. Zatem pierwsze wywołanie daje nam funkcję A(1, 299) – to jest nasz krok pierwszy.
Kolejno wszystkie następne wywołania będą miały n parzyste, ponieważ 299 jest potęgą dwójki, a każda potęga dwójki jest parzysta. Aby znaleźć liczbę tych wywołań, obliczamy logarytm dwójkowy z 299, co daje nam 99.
Czyli łącznie mamy: 1 wywołanie dla n nieparzystego plus 99 wywołań dla n parzystych – razem 100 wywołań.
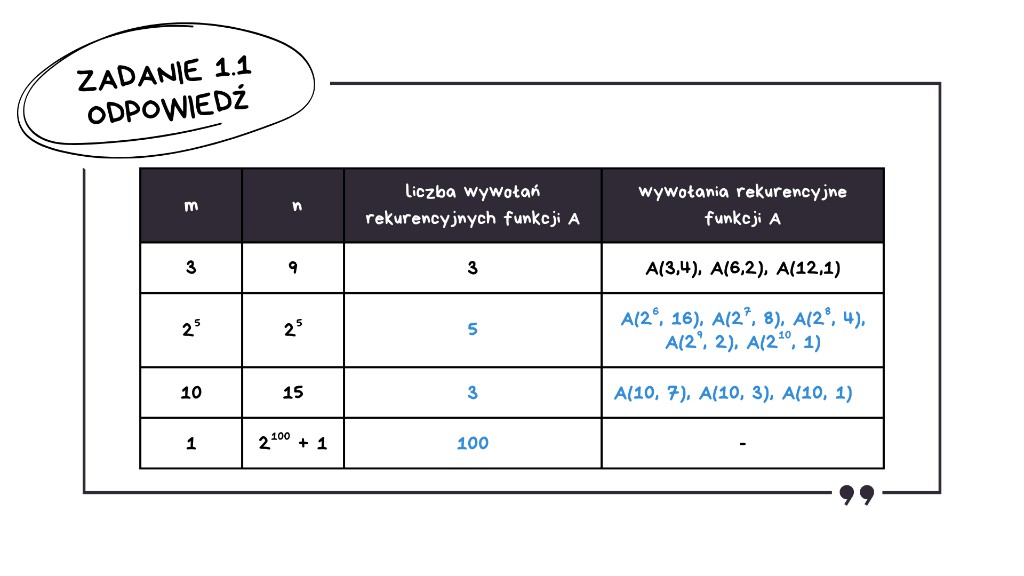
Zadanie 1.2: Analiza działania funkcji A(m,n)
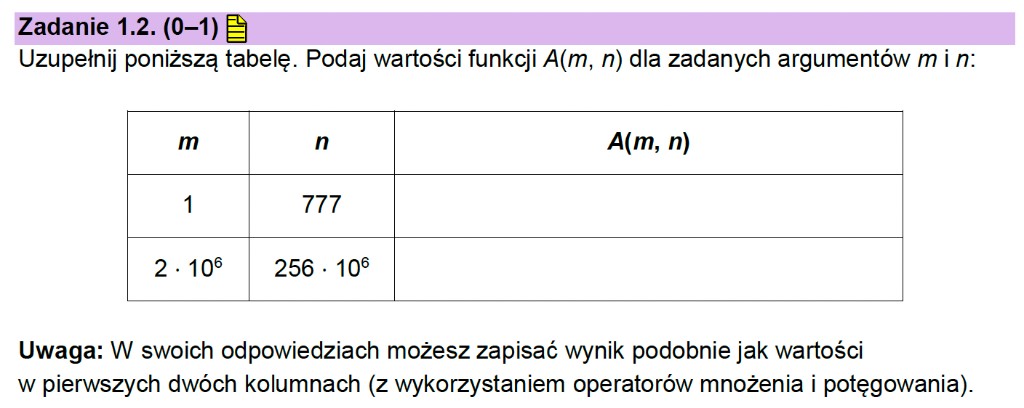
Mamy do uzupełnienia tabelę z wartościami funkcji A dla zadanych argumentów. Tym razem nie wystarczy wypisać samych wywołań – musimy doliczyć się do konkretnego wyniku, a w zapisie odpowiedzi możemy korzystać z operatorów mnożenia i potęgowania.
Pierwszy wiersz: A(1, 777)
Tutaj ponownie mamy dwa sposoby – albo możemy liczyć ręcznie, albo przepisać funkcję do programu i go uruchomić.
Zacznijmy od pierwszego sposobu, czyli ręcznego wypisywania kolejnych wywołań. Ten sposób jest zdecydowanie bardziej czasochłonny i podatny na błędy, ale za to daje nam pełne zrozumienie, jak funkcja działa.
Startujemy od funkcji A(1, 777). n jest nieparzyste, więc wywołujemy funkcję A(m, (n-1)/2), czyli A(1, 388). Teraz n jest parzyste, więc wywołujemy funkcję A(2·m, n/2), czyli A(2, 194).
Kontynuujemy w analogiczny sposób dla kolejnych wywołań.

Dotarliśmy do funkcji A(64, 1) – jednak to nie koniec. Musimy teraz cofnąć się w tej rekurencji, aby uzyskać wynik dla początkowej funkcji A(1, 777).

Drugi wiersz: A(2 · 106, 256 · 106)
Gorzej sytuacja wygląda dla kolejnego przykładu – wywołań będzie tutaj całkiem sporo. Tutaj możemy zademonstrować drugi sposób, który pewnie najczęściej wybierają maturzyści pod presją czasu.
Zobaczmy przykładową realizację w języku Python, co po prostu jest odzwierciedleniem naszej definicji funkcji A.

Po uruchomieniu programu uzyskujemy 512 i 12 zer, co możemy zapisać jako 512 · 1012 – żeby na pewno nie pominąć żadnego zera.

Zadanie 1.3: Wywołania rekurencyjne funkcji A
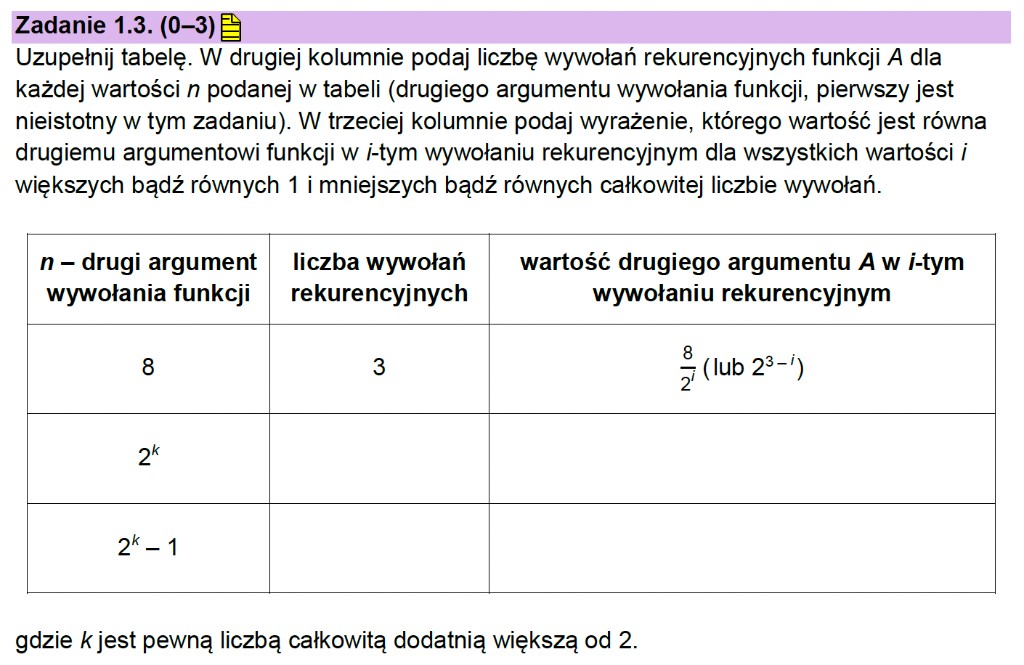
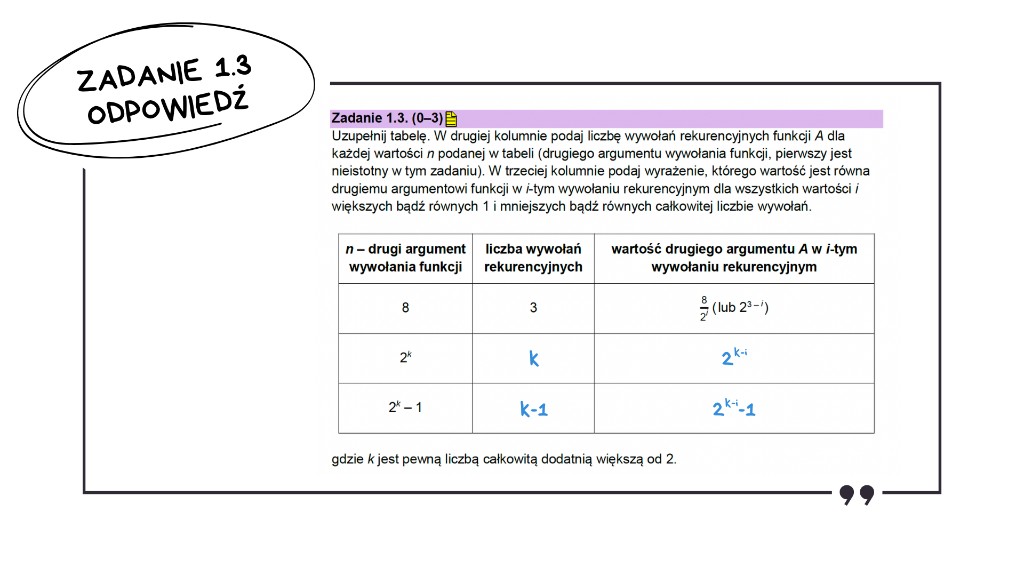
W tym podpunkcie musimy określić liczbę wywołań rekurencyjnych dla podanej wartości n oraz wartość drugiego argumentu, czyli n, w i-tym wywołaniu rekurencyjnym.
Pytanie, które mogłoby się na początku pojawić: co zrobić z pierwszym argumentem, czyli m? W końcu autor nigdzie go tutaj nie podaje. Zwróćmy jednak uwagę, że ten argument nie ma żadnego wpływu na liczbę wywołań rekurencyjnych.
Spójrzmy jeszcze raz na wzór: wszystkie warunki dotyczą n. Argument m ma jedynie wpływ na samą wartość wyniku, ale nie na liczbę wywołań.
Warto też zauważyć, że w tym zadaniu – już w podpunkcie 1.3 – musimy podać wzór na wartość n w i-tym wywołaniu rekurencyjnym. Tutaj nasz program w Pythonie już nam nie pomoże, bo nie poda nam wzoru ogólnego. I właśnie dlatego zrozumienie działania całej funkcji jest tutaj kluczowe – a mamy do zdobycia aż trzy punkty.

Jak znaleźć liczbę wywołań rekurencyjnych?
Musimy wykonywać dzielenie całkowite n przez 2:
- jeśli n jest nieparzyste, zmniejszamy je o 1 i dzielimy przez 2,
- jeśli n jest parzyste, dzielimy przez 2.
W obu przypadkach jest to dzielenie całkowite – inaczej można powiedzieć, że obliczamy ⌊n/2⌋, czyli podłogę z n przez 2.
Analiza przykładu z zadania
Wartość n wynosi 8. W następnym wywołaniu n będzie równe 4, potem 2, a następnie 1. Mamy zatem trzy wywołania rekurencyjne. Nasz sposób działa.
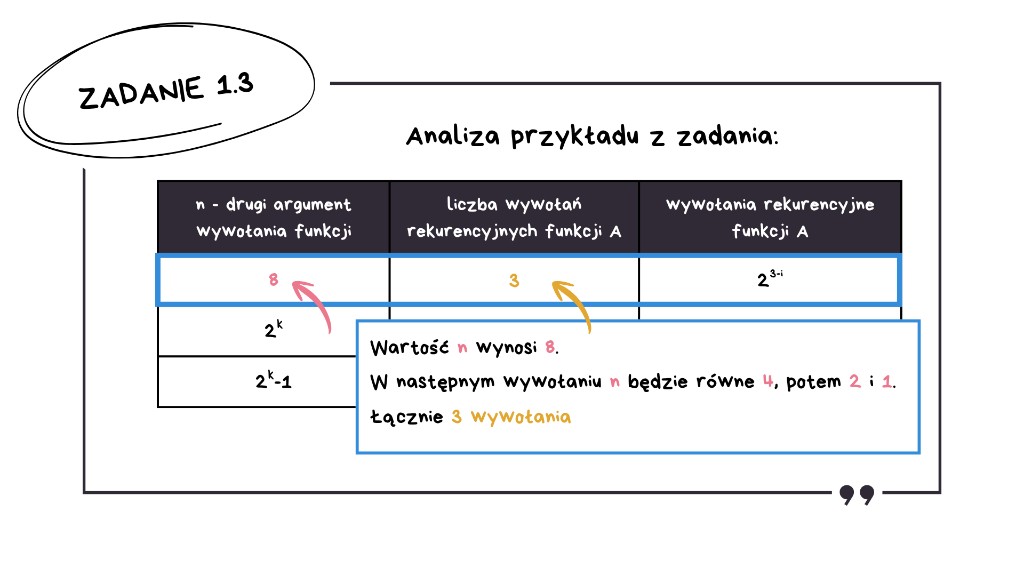
Jak znaleźć wzór na wartość n w i-tym wywołaniu? Trzeba skorzystać z faktu, że za każdym razem dzielimy przez 2. Liczba 8 jest potęgą dwójki – to 23. Dzielenie 2x przez 2 daje 2x−1. Stąd bierze się wzór: 23−i, gdzie i jest numerem wywołania.
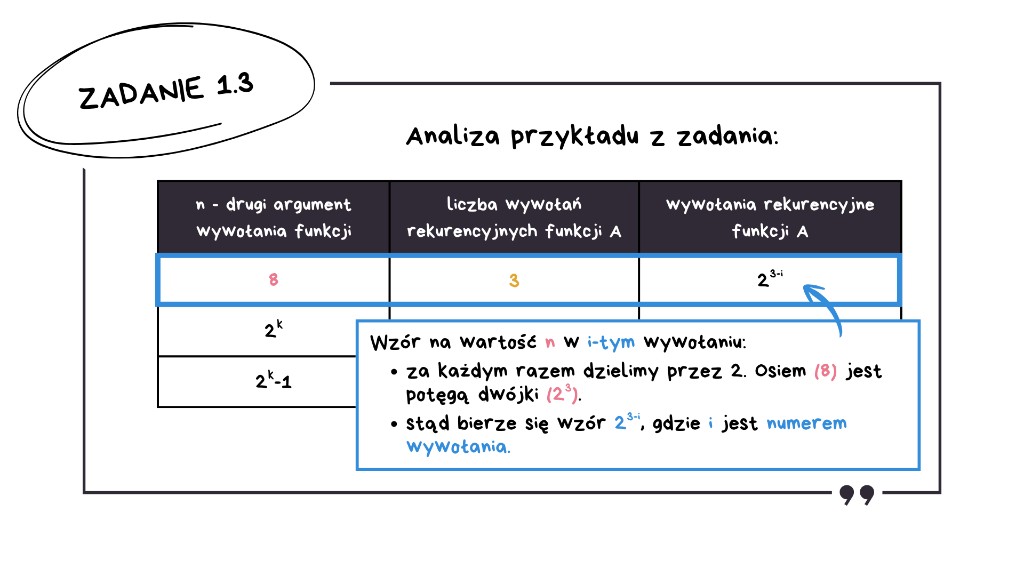
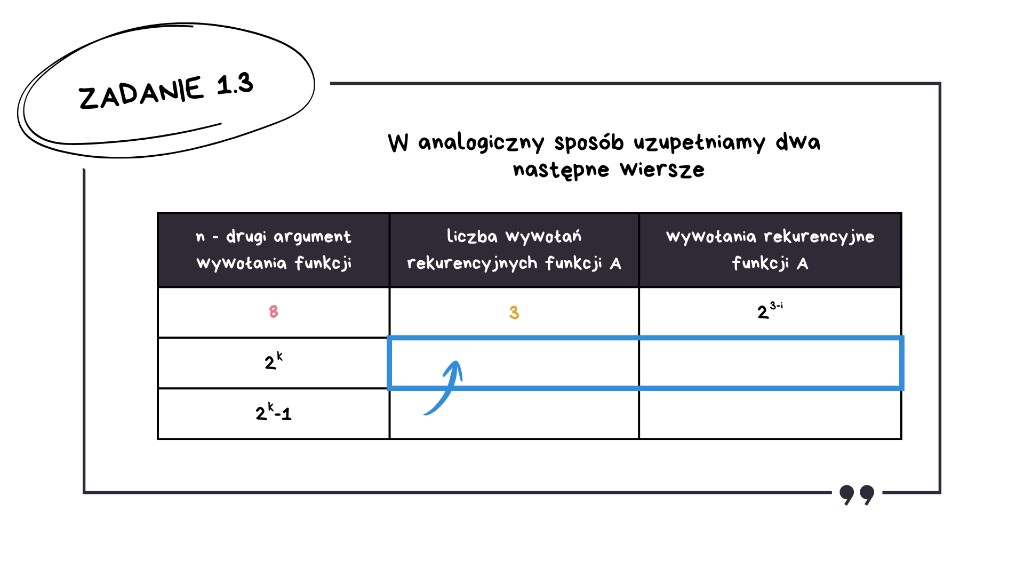
Kolejne wiersze tabeli
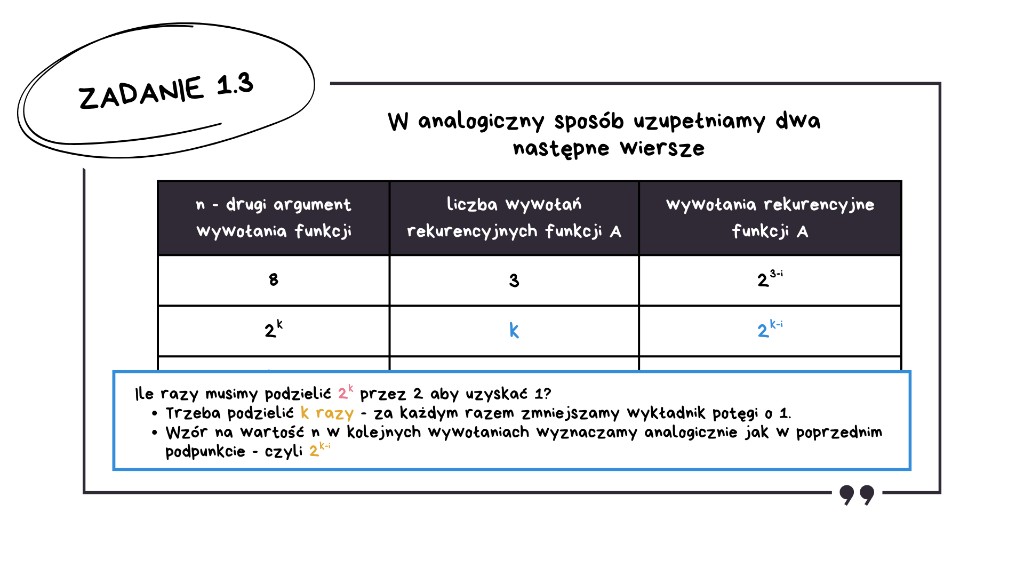
Dla n = 2k
Ile razy musimy podzielić 2k przez 2, aby uzyskać 1? Trzeba podzielić k razy – za każdym razem zmniejszamy wykładnik potęgi o 1. Wzór na wartość n w kolejnych wywołaniach wyznaczamy analogicznie jak poprzednio: 2k−i.
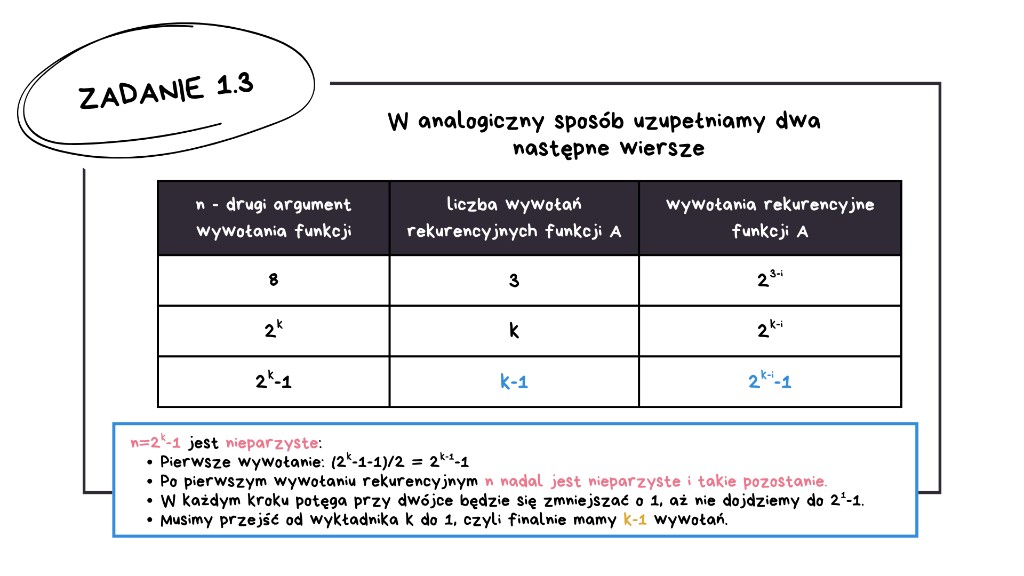
Dla n = 2k − 1
Tutaj sytuacja lekko się komplikuje – mamy nieparzyste n. Zobaczmy, co się stanie po pierwszym wywołaniu. Obliczamy: (2k − 1 − 1) / 2, co daje 2k−1 − 1. Czyli po pierwszym wywołaniu rekurencyjnym n nadal jest nieparzyste. Widać, że w każdym kolejnym wywołaniu również będzie nieparzyste.
W każdym kroku wykładnik przy dwójce zmniejsza się o 1, aż dojdziemy do 21 − 1, czyli do 1. Musimy przejść od wykładnika k do 1, a zatem łącznie mamy k − 1 wywołań.
Ciekawostka: algorytm mnożenia metodą rosyjskich chłopów
Algorytm, który analizowaliśmy, to algorytm mnożenia metodą rosyjskich chłopów. Jak widać, nie jest to algorytm wymagany na maturze i autor nie podał tej nazwy w zadaniu – maturzysta nie mógł go więc znać z góry.
Co ciekawe jednak – i to mały plus dla nas – ten sam algorytm, w wersji nieco prostszej, bo iteracyjnej, pojawia się w naszym przygotowaniu już od lat. Jest to zadanie 3.2.4 w module trzecim, gdzie ten sam algorytm jest rozpisany w postaci listy kroków. Kto przerabiał go niedawno, mógł na to wpaść. Natomiast raczej niemożliwe jest, żeby znać na pamięć wszystkie zadania spośród 940, które aktualnie są dostępne na platformie.


Zadanie 2: Dodawanie – Matura z Informatyki 2026
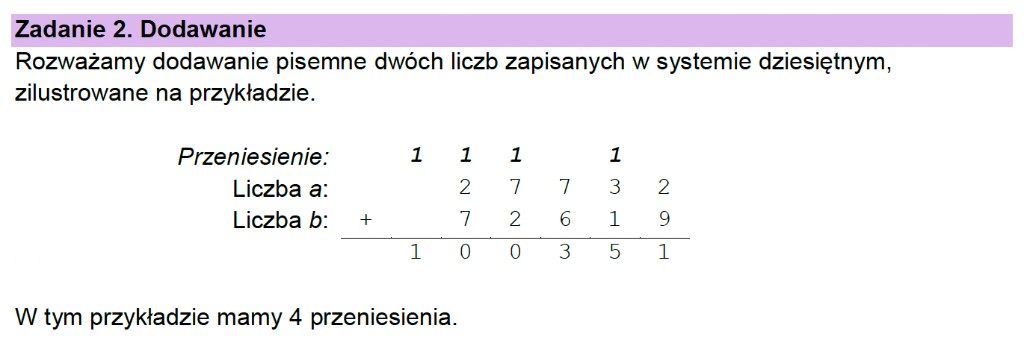
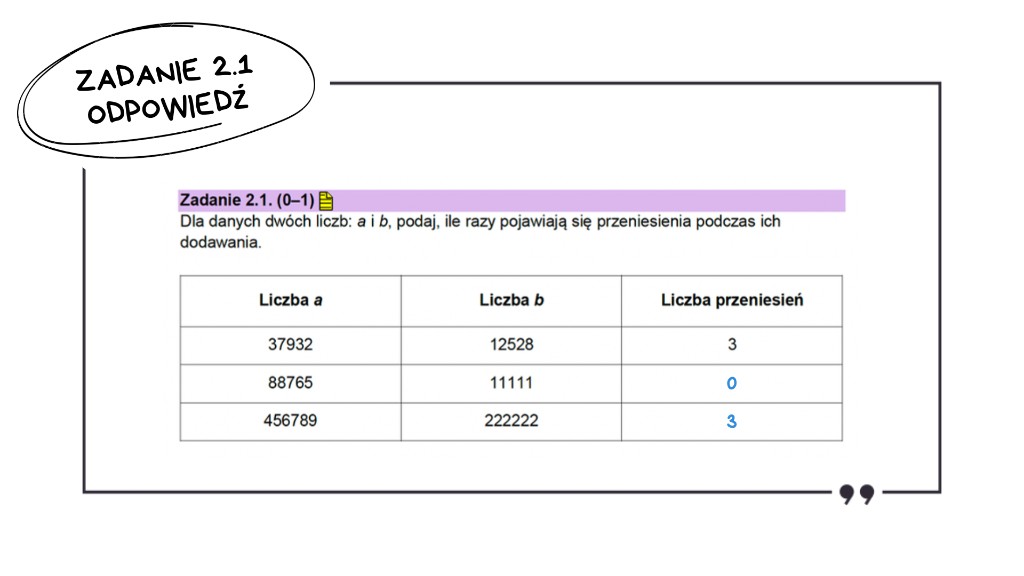
Zadanie 2.1: Tabela z liczbą przeniesień — omówienie
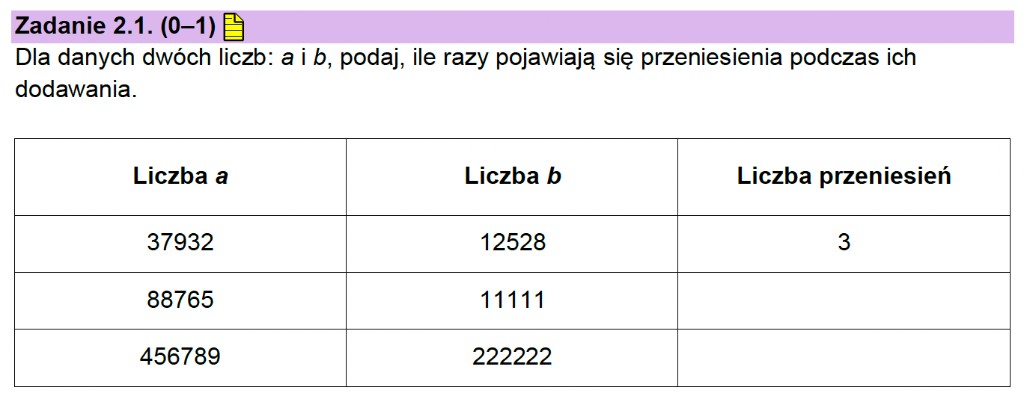
Aby rozwiązać zadanie, wystarczy przeprowadzić klasyczne dodawanie pisemne i zliczyć przeniesienia. Pomijam pierwszy przykład, bo to banał.
Drugi wiersz: 88 765 + 11 111
Liczymy od końca, cyfra po cyfrze:

5 + 1 = 6 – brak przeniesienia,
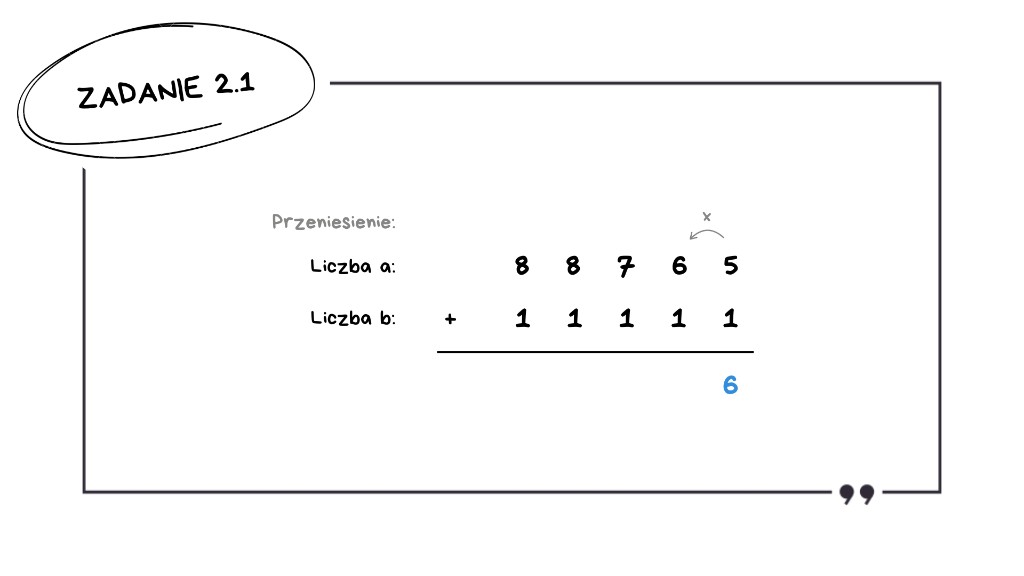
6 + 1 = 7 – brak przeniesienia,
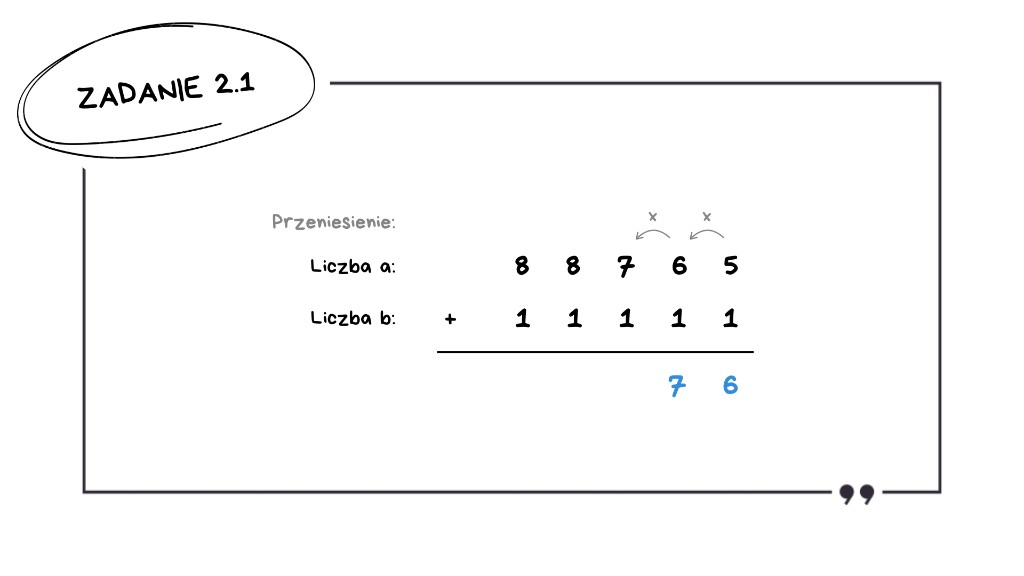
7 + 1 = 8 – brak przeniesienia,
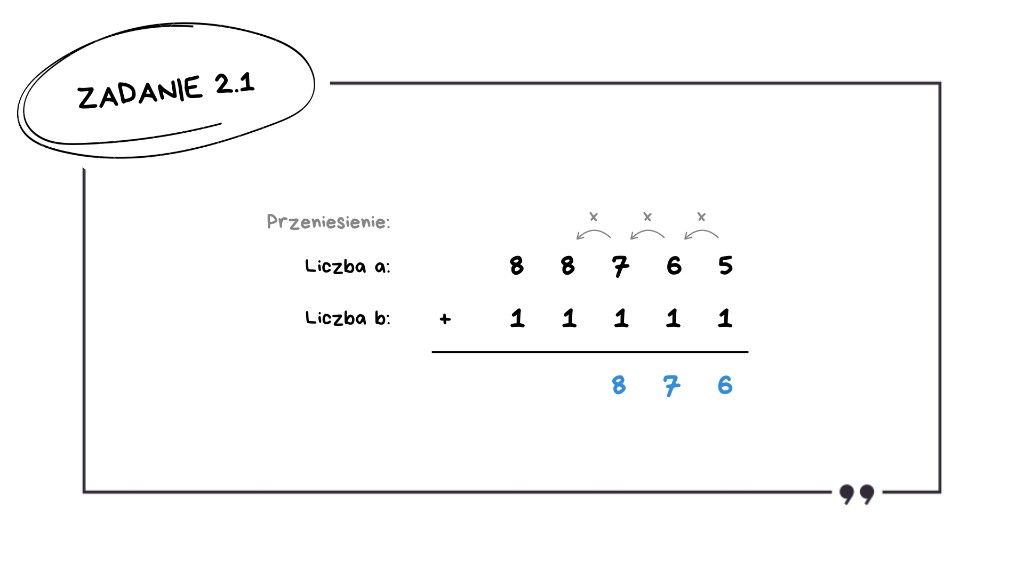
8 + 1 = 9 – brak przeniesienia,
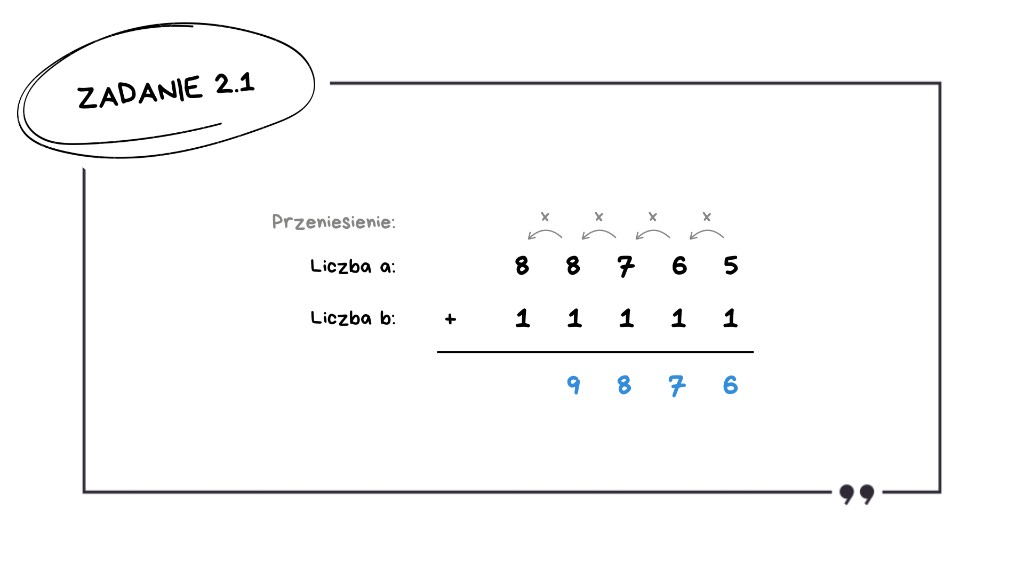
8 + 1 = 9 – brak przeniesienia.
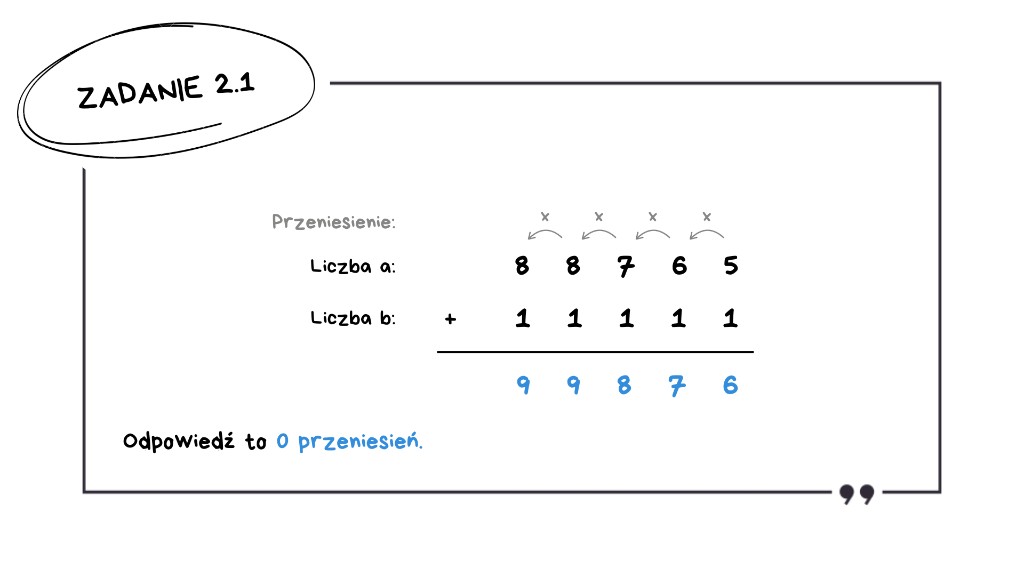
Wynik to 0 przeniesień.
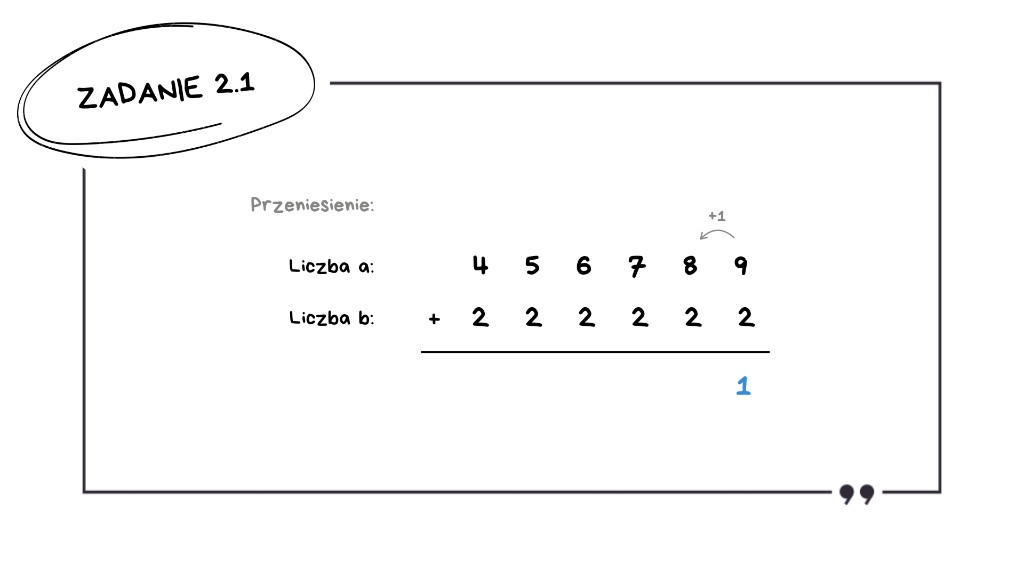
Trzeci wiersz: 456 789 + 222 222
Tutaj sytuacja jest ciekawsza:

9 + 2 = 11 – mamy pierwsze przeniesienie,
8 + 2 + 1 = 11 – mamy drugie przeniesienie,
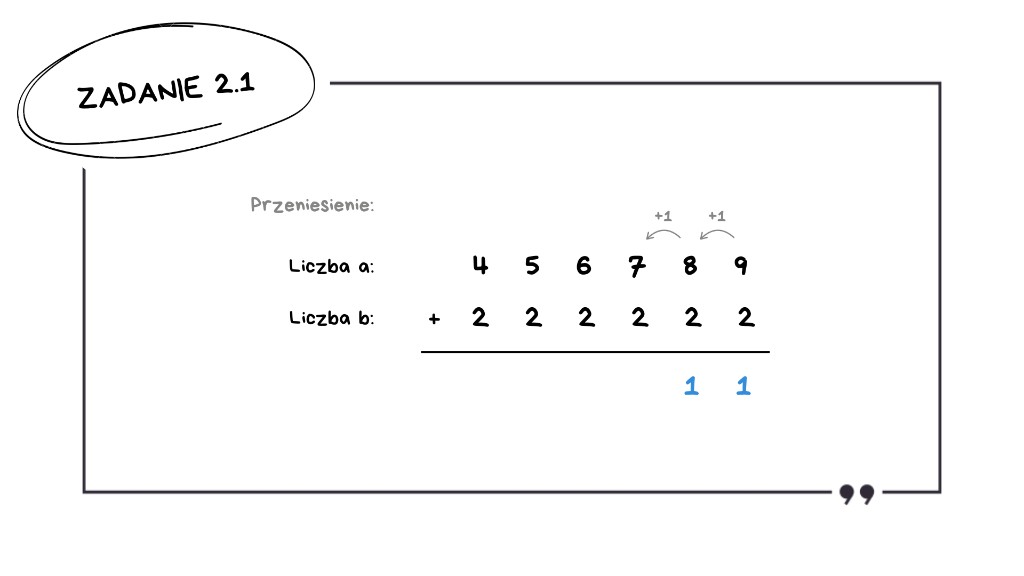
7 + 2 + 1 = 10 – mamy trzecie przeniesienie,
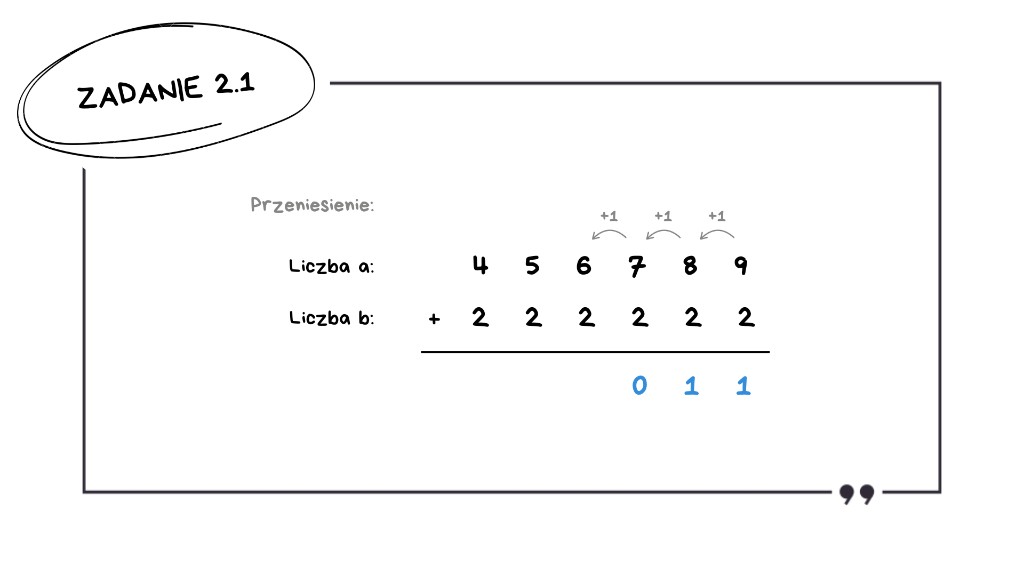
6 + 2 + 1 = 9 – brak przeniesienia,
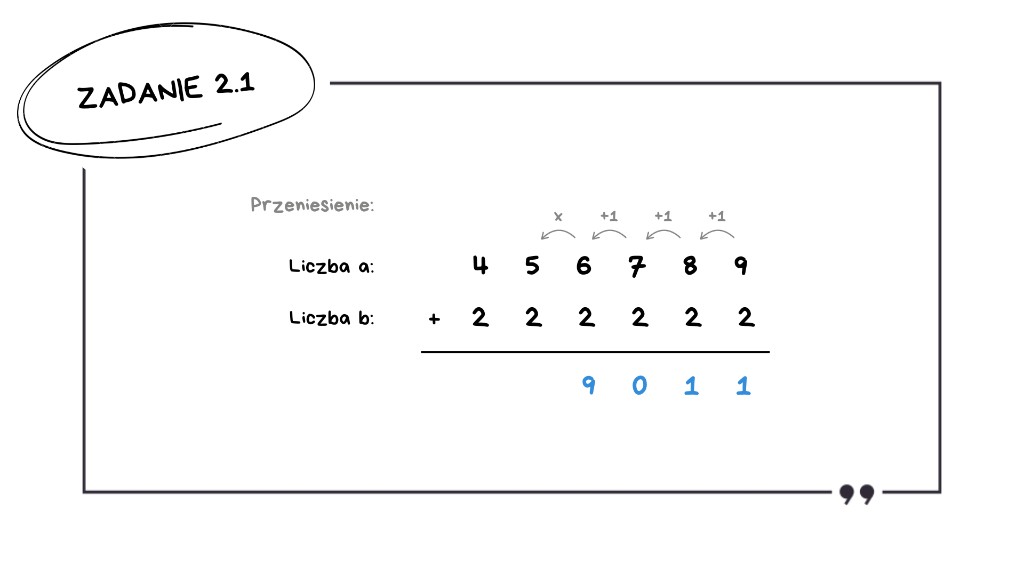
5 + 2 = 7 – brak przeniesienia,
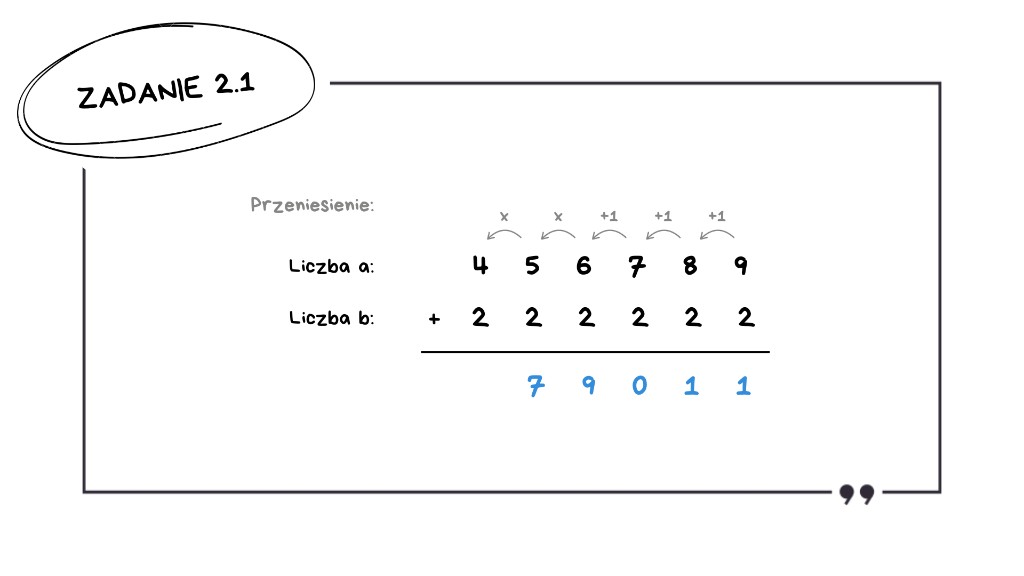
4 + 2 = 6 – brak przeniesienia.
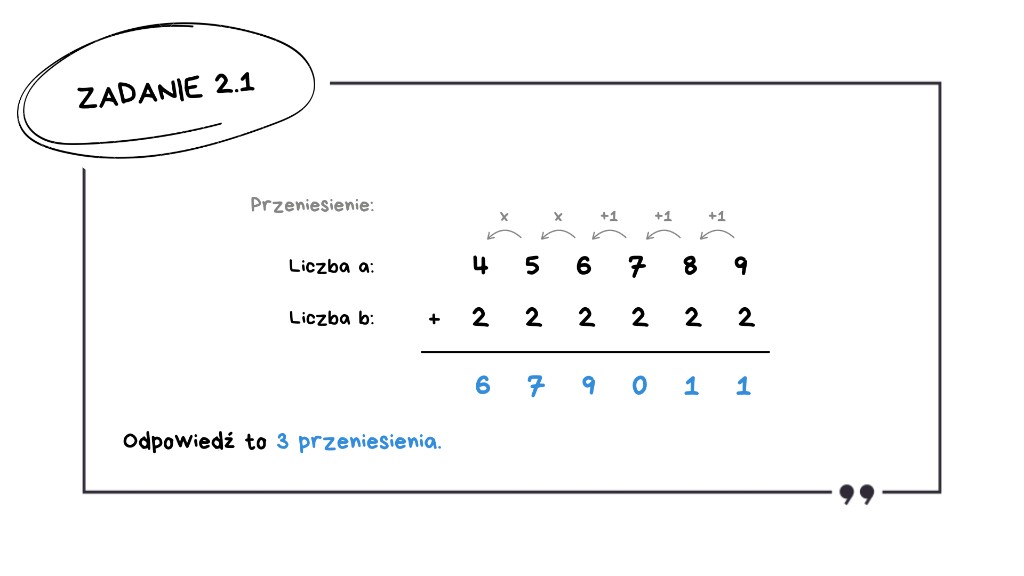
Wynik to 3 przeniesienia.
Zadanie 2.2: Algorytm obliczający liczbę przeniesień — omówienie

Klucz do rozwiązania – modulo i dzielenie całkowite
W tym zadaniu będziemy używać:
- operatora modulo do wyciągania ostatniej cyfry liczby,
- operatora dzielenia całkowitego przez 10 do tego, żeby tej ostatniej cyfry się pozbyć i przejść do kolejnego rzędu wielkości.
Czyli absolutne podstawy z modułu pierwszego, z lekcji pierwszej. Prościej się nie dało.
Konstrukcja algorytmu
Skoro a i b mają tę samą liczbę cyfr, możemy od razu przejść do dodawania. Działając tak jak przy dodawaniu pisemnym, sumujemy osobno cyfry kolejnych rzędów: jedności, dziesiątek, setek i dalej w lewo.
Cyfry wyciągamy w pętli, dopóki a jest większe od 0. W każdej iteracji wyciągamy ostatnią cyfrę a i b za pomocą operatora modulo, a następnie dzielimy obie liczby całkowicie przez 10, żeby przejść do kolejnego rzędu.
Sumowanie cyfr to zwykłe dodawanie – należy tylko pamiętać o dodaniu przeniesienia z poprzedniej iteracji. Najgorszy przypadek to:
- 9 + 9 = 18 – czyli przeniesienie wynosi 1,
- 9 + 9 + 1 = 19 – czyli przeniesienie nadal wynosi co najwyżej 1.
Na koniec sprawdzamy, czy pojawiło się przeniesienie.
Tak prezentuje się realizacja w języku Python:

Zadanie 3: Pary słów – Matura z Informatyki 2026

Zadanie 3.1: Największa suma kodów ASCII

Super proste zadanie – kody ASCII to znowu jedna z pierwszych lekcji.
Co musimy zrobić?
Stworzyć dedykowaną funkcję, która obliczy sumę kodów ASCII dla podanego słowa – szybkie i super proste. Używamy oczywiście funkcji ord, zamieniającej znaki na kody ASCII. Następnie analizujemy wyniki w prostej pętli przechodzącej przez nasze dane i sprawdzamy za każdym razem wartość bezwzględną różnicy.
Tworzymy funkcję oblicz_sume_ascii, której zadaniem jest obliczenie sumy kodów ASCII wszystkich znaków w podanym słowie. Wewnątrz funkcji ustawiamy zmienną suma na 0, a następnie przechodzimy pętlą po każdym znaku w słowie. Dla każdego znaku używamy funkcji ord, która zwraca jego kod ASCII, i dodajemy tę wartość do zmiennej suma. Na końcu funkcja zwraca obliczoną sumę.
Następnie przechodzimy do funkcji znajdz_pare_z_najwieksza_roznica_ascii. To ona odpowiada za znalezienie pary słów, dla której różnica między sumami kodów ASCII jest największa.
Na początku ustawiamy zmienną najwieksza_roznica na -1, żeby każda poprawnie obliczona różnica mogła ją zastąpić. Tworzymy też dwie zmienne: najlepsze_slowo_1 i najlepsze_slowo_2, w których będziemy zapisywać aktualnie najlepszą parę słów.
Przechodzimy pętlą po wszystkich parach słów zapisanych w liście. Dla każdej pary osobno obliczamy sumę kodów ASCII pierwszego i drugiego słowa, korzystając z wcześniej napisanej funkcji. Następnie obliczamy wartość bezwzględną różnicy tych sum za pomocą funkcji abs.
Jeżeli obliczona różnica jest większa niż dotychczasowa wartość zmiennej najwieksza_roznica, aktualizujemy wszystkie trzy informacje: największą różnicę oraz oba słowa, które tę różnicę dały. Po sprawdzeniu wszystkich par funkcja zwraca najlepszą znalezioną parę słów oraz największą różnicę.
Na koniec mamy pokazane wczytanie danych, które oczywiście realizujemy na początku implementacji programu, oraz wynik działania programu.
Rozwiązanie — zadanie 3.1 (Python):
Odpowiedź:
gpeeazeugmvsbzwsrxfplqdbakoxxe lhpbmoirdm 2206
Zadanie 3.2: Największa suma wszystkich wystąpień


Naszym celem jest znalezienie pary słów z największą liczbą wspólnych liter. Wspólne litery według wzoru to mniejsza z dwóch wartości: liczby wystąpień danej litery w słowie s1 i liczby wystąpień tej samej litery w słowie s2.
Strategia rozwiązania
Czyli co będziemy robić: dla każdej litery alfabetu policzymy liczbę jej wystąpień w obu słowach, wybierzemy mniejszą z tych dwóch wartości i dodamy ją do ogólnej sumy.
Pomocne będzie operowanie na zmiennej przechowującej cały alfabet lub szybkie działanie na kodach ASCII. Przyda się też metoda count do policzenia wystąpień – choć równie dobrze możemy napisać własną funkcję zliczającą za pomocą pętli.

Najpierw tworzymy funkcję policz_wspolne_litery, która przyjmuje dwa słowa: slowo_1 i slowo_2. Wewnątrz funkcji ustawiamy zmienną liczba_wspolnych_liter na 0 – będzie ona przechowywać łączną liczbę wspólnych liter dla danej pary.
Następnie tworzymy zmienną alfabet, w której zapisujemy wszystkie małe litery alfabetu angielskiego. Dzięki temu możemy łatwo przejść pętlą po każdej możliwej literze. Dla każdej litery sprawdzamy, ile razy występuje ona w pierwszym słowie i ile razy w drugim, korzystając z metody count.
Jeżeli na przykład litera występuje 3 razy w pierwszym słowie i 5 razy w drugim, to wspólne są tylko 3 wystąpienia. Dlatego do wyniku dodajemy mniejszą z tych dwóch wartości, używając funkcji min. Po sprawdzeniu wszystkich liter alfabetu funkcja zwraca łączną liczbę wspólnych liter dla podanej pary słów.
Następnie przechodzimy do kolejnej funkcji: znajdz_pare_z_najwieksza_liczba_wspolnych_liter. To ona odpowiada za znalezienie najlepszej pary w całym pliku.
Na początku ustawiamy zmienną najwieksza_liczba_wspolnych_liter na -1, aby pierwsza sprawdzana para mogła od razu zostać zapisana jako aktualnie najlepsza. Tworzymy też zmienne najlepsze_slowo_1 i najlepsze_slowo_2, w których będziemy przechowywać słowa z najlepszej dotychczas znalezionej pary.
Przechodzimy pętlą po wszystkich parach zapisanych w liście pary_slow. Dla każdej pary wywołujemy funkcję policz_wspolne_litery, która zwraca liczbę wspólnych liter dla słów s1 i s2. Jeżeli ta wartość jest większa niż dotychczasowa największa, aktualizujemy wynik i zapamiętujemy oba słowa.
Po zakończeniu pętli funkcja zwraca trzy wartości: pierwsze słowo, drugie słowo oraz największą znalezioną liczbę wspólnych liter.
Na koniec – analogicznie do poprzedniego programu – mamy wczytanie danych z pliku tekstowego i wyświetlenie wyniku.
Rozwiązanie — zadanie 3.2 (Python):
Odpowiedź:
aacbcccaacacbcabac cccccaaaacaccbabcba 18
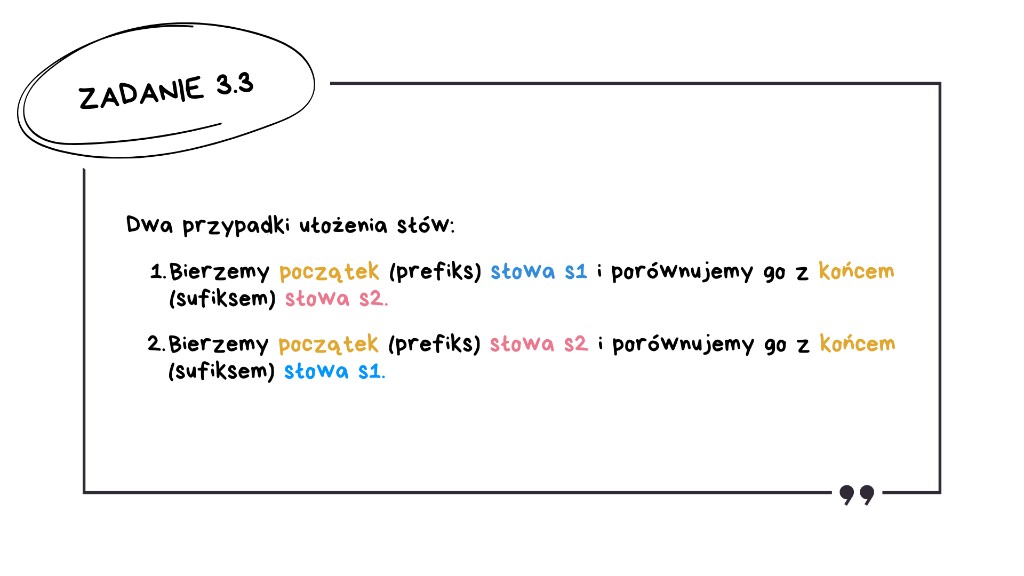
Zadanie 3.3: Najdłuższy prefiks pary słów

Najpierw musimy dobrze zrozumieć, czym jest prefiksosufiks. Interesuje nas sytuacja, w której początek jednego słowa jest taki sam jak koniec drugiego słowa.
Dla każdej pary słów sprawdzamy dwa możliwe warianty:
- Wariant pierwszy – bierzemy prefiks, czyli początek pierwszego słowa, i porównujemy go z sufiksem, czyli końcem drugiego słowa.
- Wariant drugi – działa odwrotnie: bierzemy początek drugiego słowa i porównujemy go z końcem pierwszego słowa.
Naszym celem jest znalezienie najdłuższego takiego dopasowania spośród obu wariantów.
Strategia rozwiązania
Jak to zrealizować? Rozpiszmy to po kolei:
- Po pierwsze – szukamy jednego najdłuższego dopasowania.
- Po drugie – wyznaczamy minimum z długości obu słów, bo nie ma sensu szukać dopasowań dłuższych niż krótsze z nich.
- Po trzecie – pętlę najlepiej zacząć od największej możliwej długości i schodzić w dół. Dzięki temu pierwsze znalezione dopasowanie będzie od razu najdłuższe.
- Po czwarte – wybieramy maksymalny wynik spośród obu wariantów.
- Po piąte – zapisujemy tylko te pary, dla których wynik wynosi co najmniej 5 znaków.
Implementacja
Tworzymy funkcję najdluzsze_dopasowanie. Przyjmuje ona dwa słowa: jedno traktujemy jako źródło prefiksu (czyli początku), a drugie jako źródło sufiksu (czyli końca).
Na początku obliczamy maksymalną możliwą długość dopasowania. Nie ma sensu sprawdzać fragmentu dłuższego niż krótsze z tych dwóch słów, dlatego bierzemy minimum z ich długości. Następnie przechodzimy pętlą od tej największej możliwej długości w dół do jedynki. W każdej iteracji porównujemy prefiks i sufiks – jeżeli są sobie równe, znaleźliśmy dopasowanie i od razu zwracamy jego długość. Jeżeli pętla zakończy się bez żadnego dopasowania, funkcja zwraca 0.
Przechodzimy do funkcji znajdz_pary_z_dopasowaniem. Ta funkcja analizuje wszystkie pary słów z pliku. Dla każdej pary, czyli dla słów s1 i s2, liczymy dwa dopasowania:
- pierwsze sprawdza, jak długi prefiks słowa
s1pasuje do sufiksu słowas2, - drugie sprawdza sytuację odwrotną.
Następnie wybieramy większą z tych dwóch wartości. Jeżeli najdłuższe znalezione dopasowanie ma co najmniej 5 znaków, dodajemy tę parę do wyników.
Na końcu wczytujemy dane z pliku pary.txt i uruchamiamy funkcję.
Rozwiązanie — zadanie 3.3 (Python):

Tym samym zakończyliśmy zadanie 3. Możemy umieścić nasze odpowiedzi w pliku wyniki3.txt i przejść do kolejnego zadania.

Zadanie 4: Korporacja – Matura z Informatyki 2026
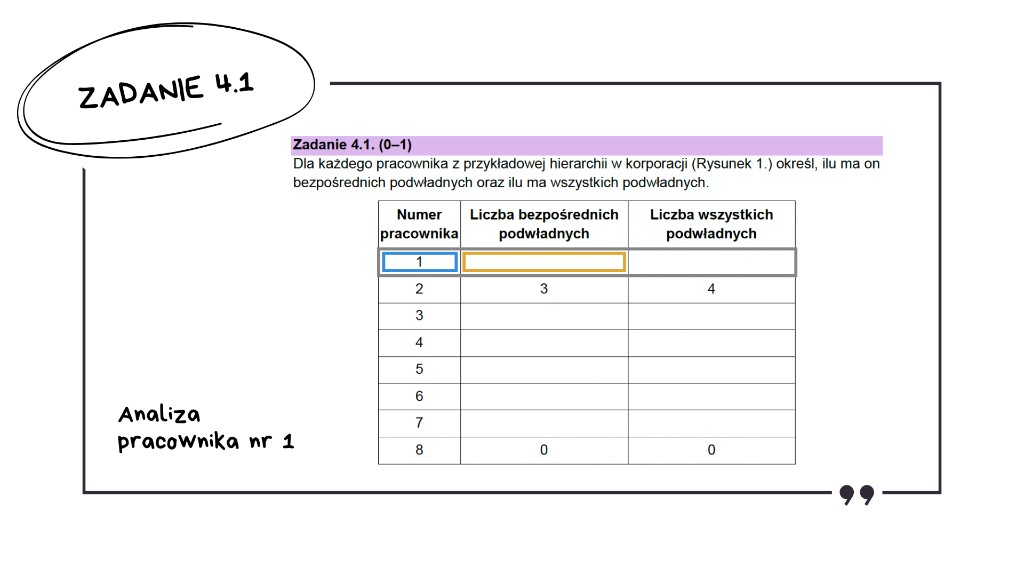
Zadanie 4.1: Tabela z liczbą podwładnych
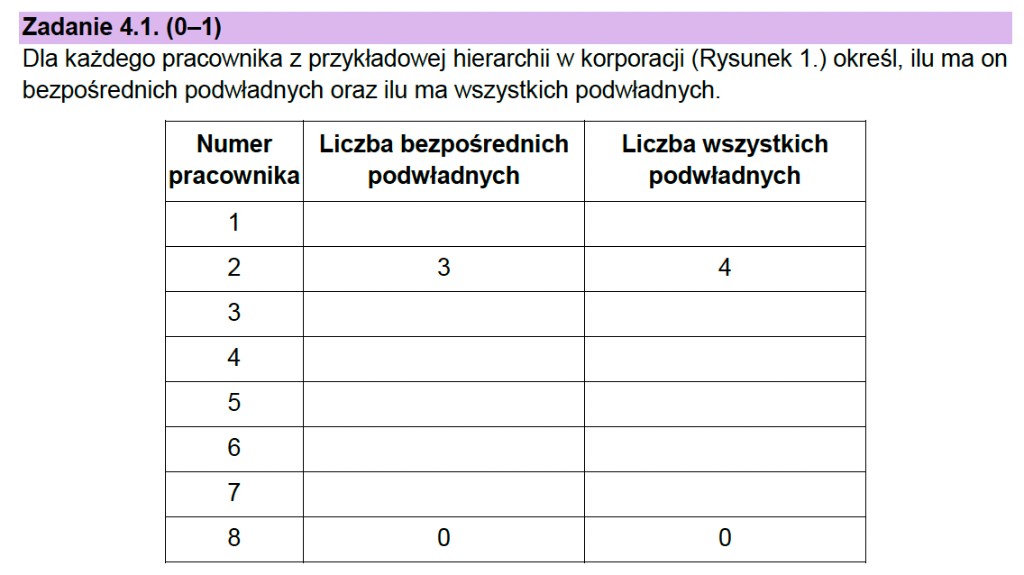
Zadanie polega na analizie struktury drzewa, gdzie każdy węzeł – oprócz prezesa – ma dokładnie jednego rodzica. Wprowadźmy sobie dwa kluczowe pojęcia:
- Podwładny bezpośredni to dziecko danego węzła, czyli bezpośrednie połączenie w dół.
- Wszyscy podwładni to całe poddrzewo zaczynające się od danego pracownika – a więc jego dzieci, dzieci jego dzieci i tak dalej.
Ręczne zliczenie bezpośrednich i wszystkich podwładnych to darmowy punkt.
Grafy na maturze – mamy je w kursie
Warto wspomnieć, że drzewo to graf – a grafy mamy przerobione w kursie już od dawna, w module drugim. Znalazły się w materiale właśnie dlatego, żeby pokryć 100% wymagań maturalnych. Wielu zdających twierdziło, że to zakres na studia i nigdy się nie trafi – a tu proszę. Opłaciło się.
Analiza tabeli krok po kroku
Wracamy do analizy tabeli i zaczynamy od pracownika numer 1. Sprawdzamy liczbę jego bezpośrednich podwładnych.
To prezes, więc odczytujemy z rysunku – ma dwóch bezpośrednich podwładnych.
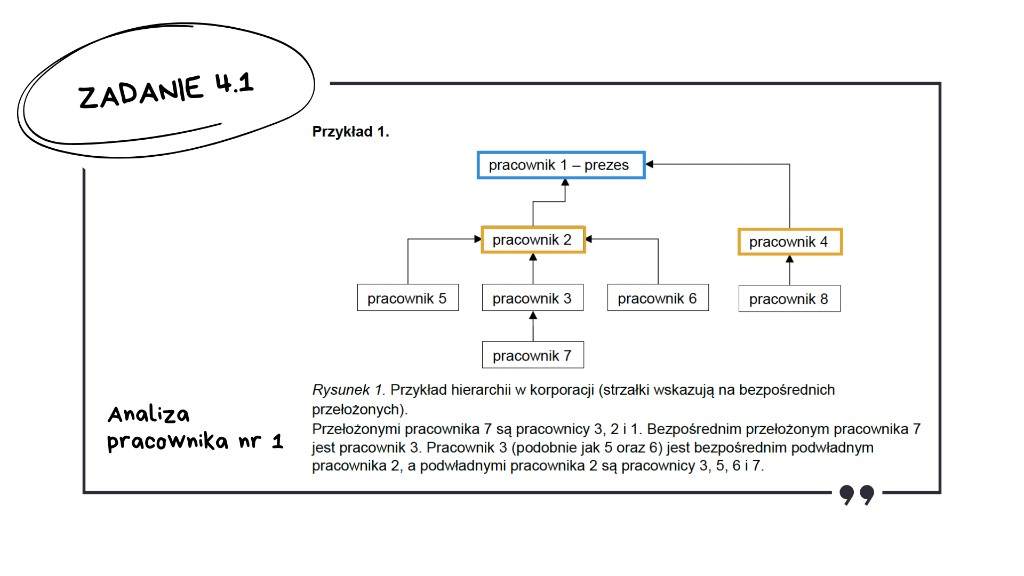
Sprawdzamy teraz liczbę wszystkich jego podwładnych.
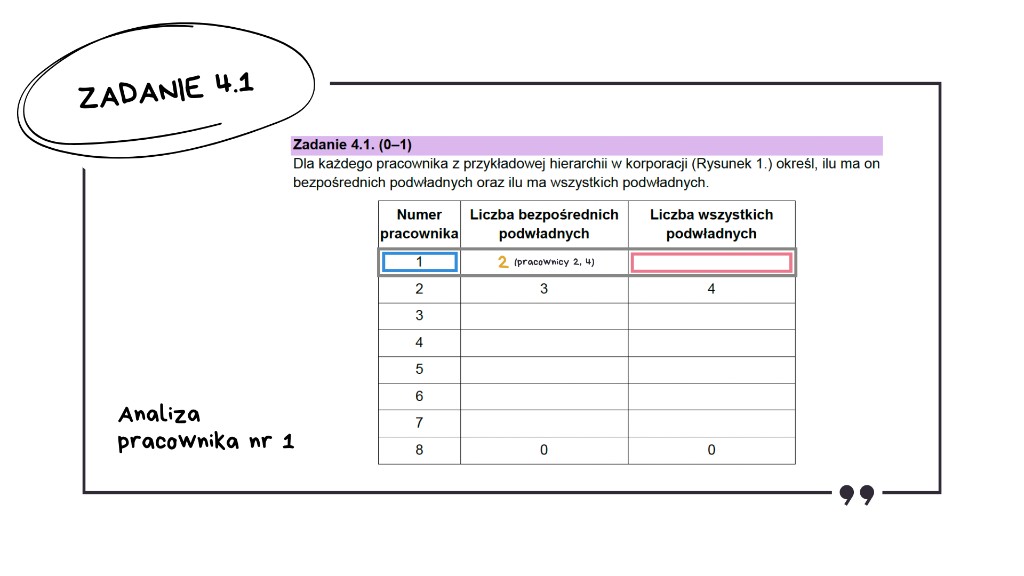
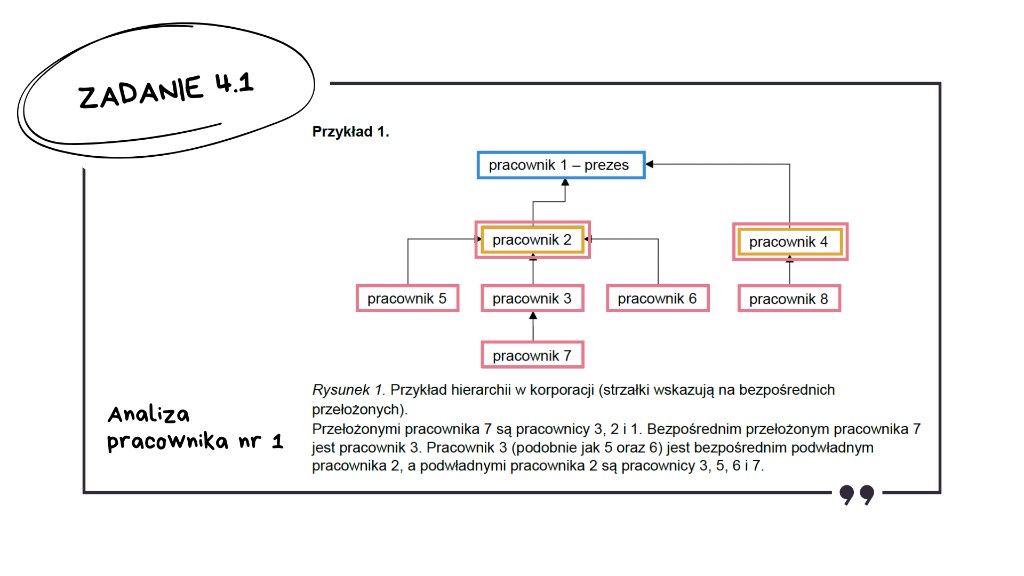
Wszyscy pracownicy poza samym prezesem są jego podwładnymi.
Przechodzimy do pracownika numer 3.
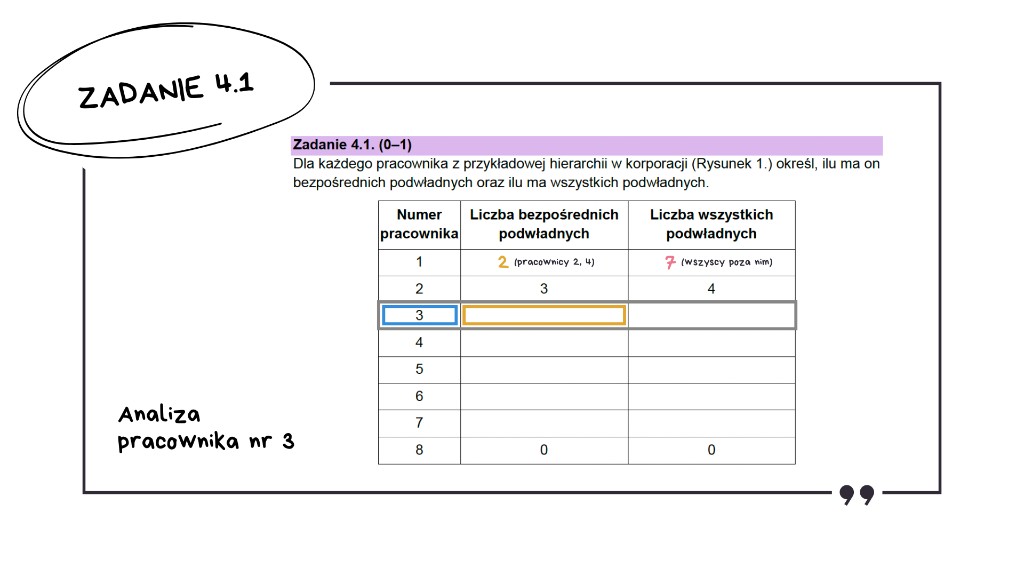
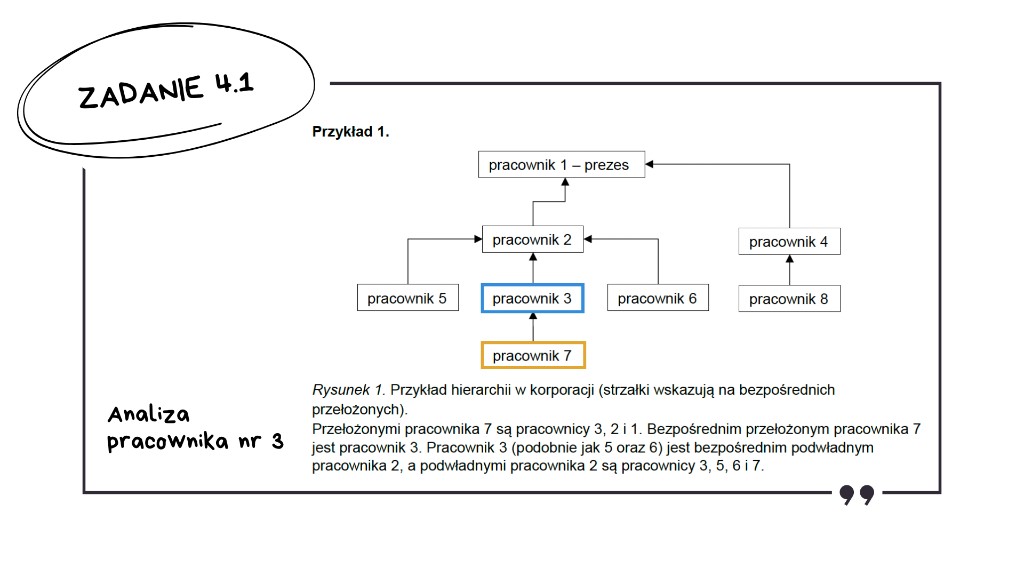
Jak widzimy, ma tylko jednego bezpośredniego podwładnego.
Sprawdzamy teraz, ilu ma wszystkich podwładnych.
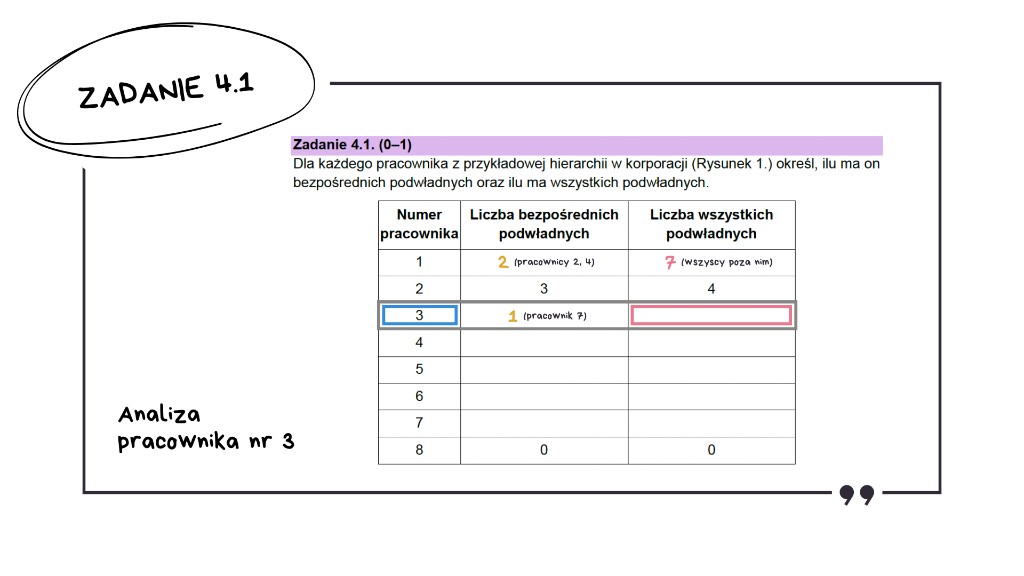
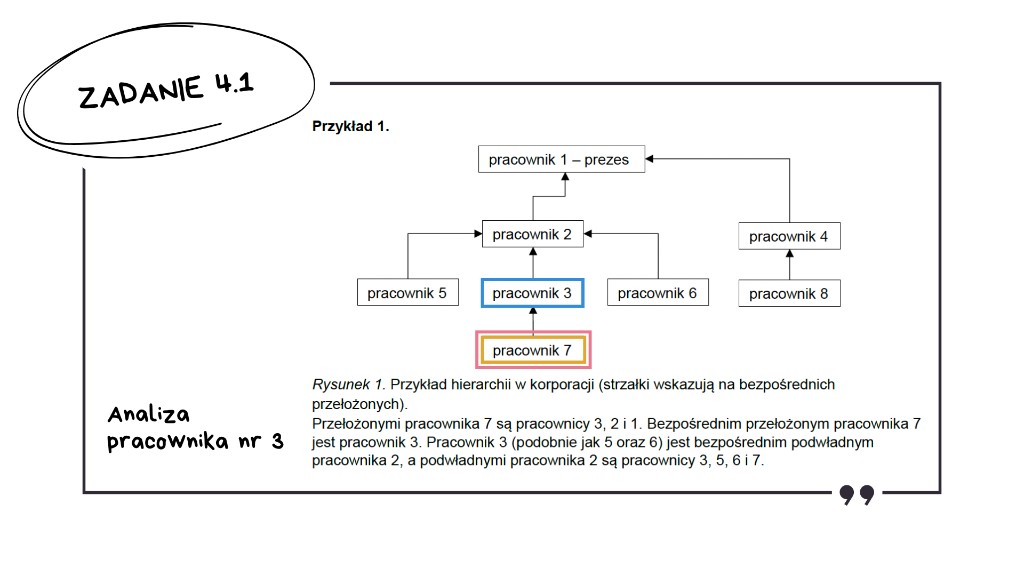
Również jednego.
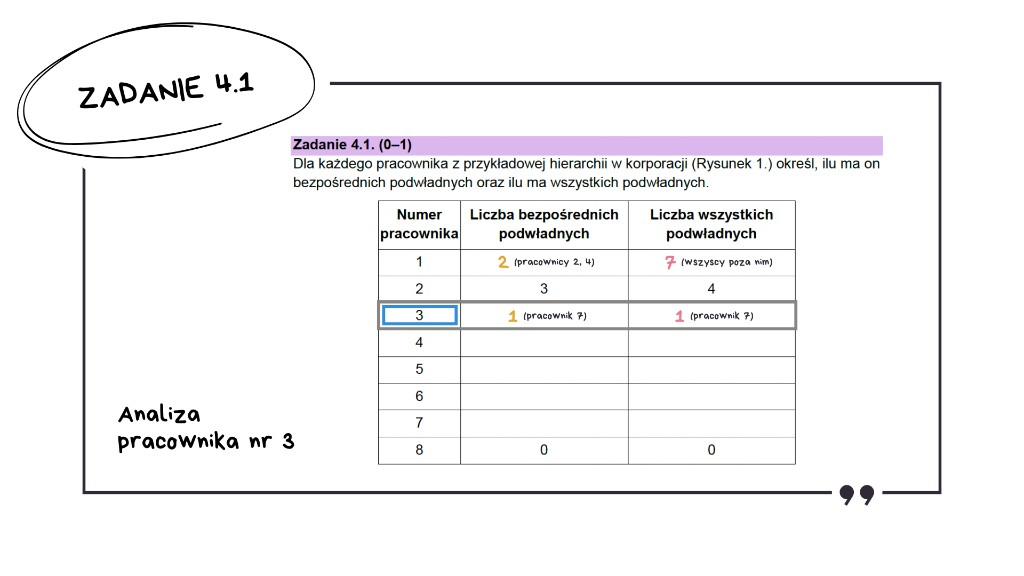
I analogicznie przechodzimy przez wszystkich pozostałych pracowników.
Mamy wyniki do zadania 4.1. Praktycznie darmowe punkty.
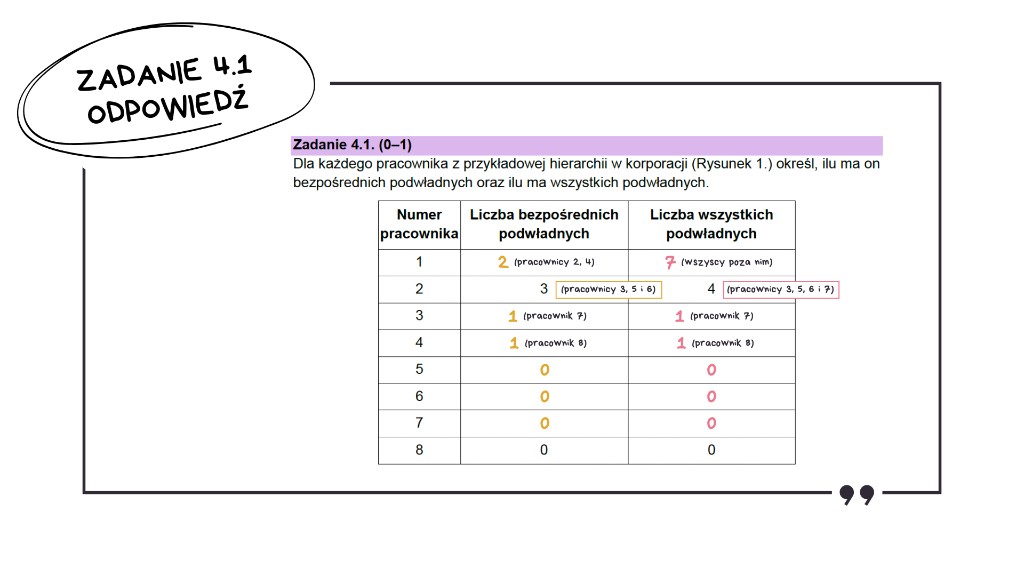
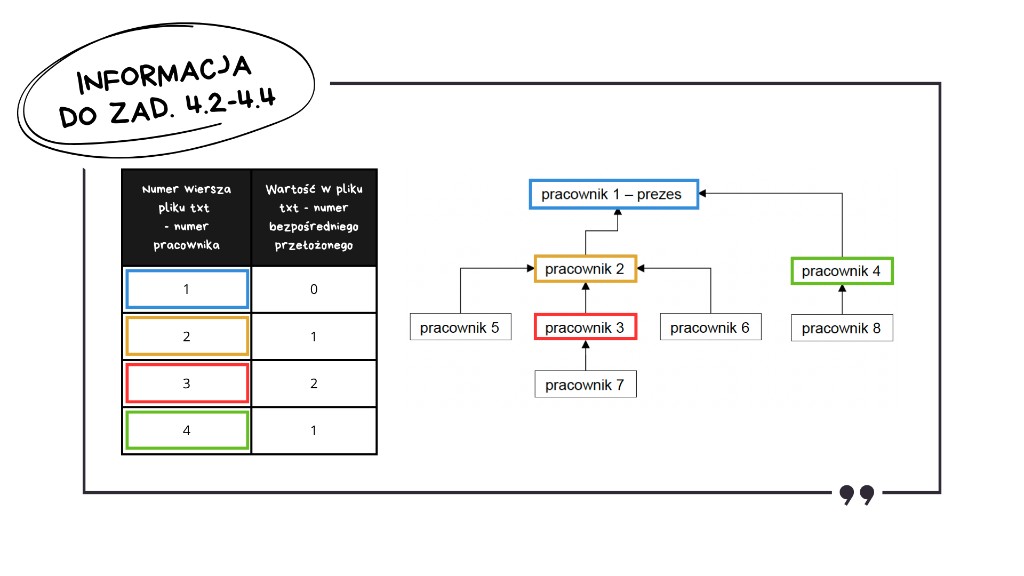
Informacja do zadań 4.2–4.4

Zanim ruszymy z rozwiązaniami, zacznijmy od dogłębnego zrozumienia danych – bez tego nie ruszymy z miejsca w kolejnych podpunktach.
W pliku korpo.txt każdy wiersz odpowiada jednemu pracownikowi i zawiera numer jego bezpośredniego przełożonego:
- Wiersz 1 zawiera
0– to oznacza brak przełożonego, czyli prezesa korporacji. - Wiersz 2 reprezentuje pracownika nr 2, którego bezpośrednim przełożonym jest pracownik nr 1, czyli sam prezes.
- Wiersz 3 – pracownik nr 3, jego bezpośrednim przełożonym jest pracownik nr 2.
- Wiersz 4 – pracownik nr 4, jego bezpośrednim przełożonym jest pracownik nr 1.
Bez zrozumienia tej struktury – że indeks wiersza to numer pracownika, a wartość w wierszu to numer jego bezpośredniego przełożonego – nie będziemy w stanie poprawnie rozwiązać żadnego z kolejnych podpunktów.
Zadanie 4.2: Pracownicy, którzy nie są przełożonymi

Schemat działania
Rozpiszmy sobie najpierw plan rozwiązania:
- Wczytujemy dane z pliku.
- Tworzymy tablicę
ma_podwladnycho długości wczytanych danych powiększonej o 1 – ponieważ pracownicy są numerowani od 1, a nie od 0. - W tablicy ustawiamy
Falsedla każdego pracownika. - Zmieniamy wartość w tablicy na
Truedla każdego przełożonego, którego odczytamy z tablicy. - Liczymy, ile osób ma przełożonego i na końcu zapisujemy odpowiedź do pliku .txt.
Implementacja
Na początku wczytujemy dane z pliku korpo.txt do tablicy dane. Następnie tworzymy tablicę ma_podwladnych o długości liczby pracowników powiększonej o 1, ponieważ pracownicy są numerowani od 1, a nie od 0. Tablica ta będzie przechowywać informację, czy dany pracownik ma przynajmniej jednego podwładnego. Na początku dla każdego pracownika ustawiamy wartość False.
Następnie przechodzimy po tablicy dane, w której zapisani są przełożeni kolejnych pracowników. Dla każdego odczytanego przełożonego ustawiamy w tablicy ma_podwladnych wartość True, ponieważ oznacza to, że ten pracownik jest czyimś przełożonym, czyli ma co najmniej jednego podwładnego.
Na końcu przechodzimy po wszystkich pracownikach od 1 do n i sprawdzamy, którzy z nich mają w tablicy ma_podwladnych wartość False. Oznacza to, że taki pracownik nie jest przełożonym żadnej osoby, czyli nie ma podwładnych. Zliczamy takich pracowników i zwracamy ich liczbę jako wynik zadania.
Odpowiedź: 25113 (liczba pracowników, która nie jest przełożonym żadnego pracownika).
Zadanie 4.3: Pracownik z największą liczbą podwładnych

Schemat działania
Początek zadania jest analogiczny jak w zadaniu 4.2. Zmienia się jednak to, co przechowujemy:
- W tablicy
bezposredni_podwladnibędziemy przechowywać dla każdego pracownika liczbę jego bezpośrednich podwładnych. - W tablicy zwiększamy licznik o 1 dla danego pracownika, jeżeli na niego trafimy (oznacza to, że jest czyimś przełożonym).
Implementacja
Na początku wczytujemy dane z pliku korpo.txt do tablicy dane. W tablicy tej zapisane są numery przełożonych kolejnych pracowników.
Następnie tworzymy tablicę bezposredni_podwladni o długości liczby pracowników powiększonej o 1, ponieważ pracownicy są numerowani od 1, a nie od 0. Tablica ta będzie przechowywać informację, ilu bezpośrednich podwładnych ma każdy pracownik. Na początku dla każdego pracownika ustawiamy wartość 0, ponieważ jeszcze nie zliczyliśmy żadnych podwładnych.
Potem przechodzimy po tablicy dane. Dla każdego pracownika odczytujemy numer jego przełożonego i zwiększamy o 1 liczbę bezpośrednich podwładnych tego przełożonego w tablicy bezposredni_podwladni.
Po zliczeniu podwładnych przechodzimy po wszystkich pracownikach od 1 do n i sprawdzamy, który z nich ma największą liczbę bezpośrednich podwładnych. Jeśli znajdziemy pracownika z większą liczbą podwładnych niż dotychczasowa największa wartość, zapamiętujemy numer tego pracownika oraz liczbę jego podwładnych.
Na końcu funkcja zwraca numer pracownika, który ma najwięcej bezpośrednich podwładnych, oraz liczbę tych podwładnych.
Odpowiedź: 2 19 (pracownik nr 2 ma 19 bezpośrednich podwładnych).
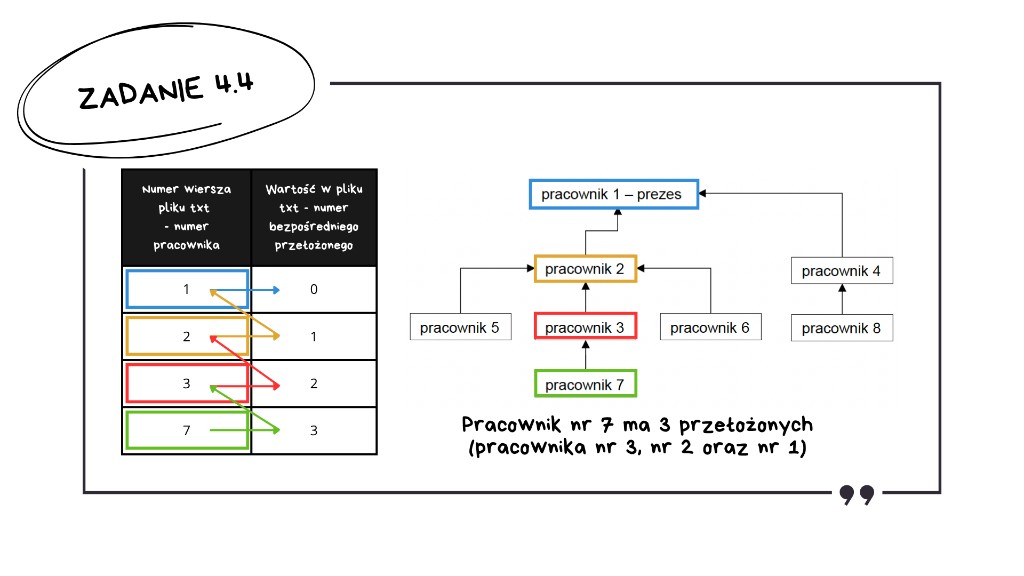
Zadanie 4.4: Pracownik z największą liczbą przełożonych

To zadanie na początku może wydawać się bardziej skomplikowane, dlatego przejdźmy przez nie krok po kroku.
Najważniejszą rzeczą do zauważenia w tym zadaniu jest to, że nie liczymy bezpośrednich przełożonych danego pracownika (każdy ma dokładnie jednego, więc zadanie byłoby trywialne), tylko wszystkich przełożonych – czyli całą ścieżkę w drzewie hierarchii od pracownika w górę, aż do prezesa.
Innymi słowy: dla każdego pracownika będziemy iść po gałęziach drzewa do góry, aż do wierzchołka drzewa, czyli prezesa. Pętla kończy się dopiero, gdy dojdziemy do prezesa, czyli natrafimy na wartość 0. Po drodze zliczamy liczbę takich przejść – nawiązując do grafów, są to po prostu kolejne krawędzie (gałęzie) drzewa, którymi wspinamy się w stronę wierzchołka drzewa. Ta liczba kroków to właśnie liczba wszystkich przełożonych danego pracownika, której szukamy.
Warto wspomnieć, że do realizacji tego zadania możemy wybrać bardziej „profesjonalną” ścieżkę – zbudować sobie pełną strukturę grafu i za pomocą rekurencji wspinać się w górę, aż natrafimy na wartość 0. Pod względem praktycznym byłoby to lepsze rozwiązanie. My jednak spróbujemy zrobić wersję iteracyjną, bo dla uczniów jest ona znacznie bardziej zrozumiała. Po prostu w pętli będziemy odszukiwać kolejnych przełożonych w naszej tablicy z danymi, dopóki nie dojdziemy do prezesa – przy okazji licząc każde przejście z jednego pracownika do drugiego. Tym samym dla każdego pracownika uzyskamy informację, ilu dokładnie ma przełożonych, a następnie wybierzemy osobę, która ma ich najwięcej.
Wczytanie danych
Na początku wczytujemy dane z pliku korpo.txt do tablicy przelozony. Na pierwszym miejscu tablicy umieszczamy wartość 0, dzięki czemu numer indeksu w tablicy odpowiada numerowi pracownika. Oznacza to, że przelozony[i] przechowuje numer bezpośredniego przełożonego pracownika i.
Kluczowa funkcja: policz_przelozonych
Kluczowym elementem rozwiązania jest funkcja policz_przelozonych, która oblicza, ilu przełożonych ma dany pracownik.
Zaczynamy od wybranego pracownika i zapisujemy go w zmiennej aktualny_pracownik. Następnie w pętli sprawdzamy, czy aktualny pracownik ma przełożonego, czyli czy przelozony[aktualny_pracownik] != 0.
Jeżeli pracownik ma przełożonego:
- przechodzimy do tego przełożonego, czyli wykonujemy
aktualny_pracownik = przelozony[aktualny_pracownik], - zwiększamy licznik przełożonych o 1.
Powtarzamy ten proces aż do momentu, gdy trafimy na pracownika, który nie ma przełożonego. W tym zadaniu oznacza to dotarcie do prezesa, dla którego wartość przełożonego wynosi 0. Funkcja zwraca liczbę przełożonych danego pracownika.
Funkcja znajdująca najlepszy wynik
Następnie w funkcji znajdz_najwieksza_liczbe_przelozonych sprawdzamy wszystkich pracowników od 1 do n. Dla każdego z nich wywołujemy funkcję policz_przelozonych i otrzymujemy liczbę jego przełożonych.
Jeżeli obliczona liczba przełożonych jest większa od dotychczasowej największej wartości, aktualizujemy zmienną najwieksza_liczba_przelozonych i ustawiamy licznik pracowników na 1, ponieważ znaleźliśmy pierwszego pracownika z nowym najlepszym wynikiem.
Jeżeli liczba przełożonych jest równa aktualnej największej wartości, zwiększamy zmienną liczba_pracownikow o 1. Oznacza to, że znaleźliśmy kolejnego pracownika, który ma tyle samo przełożonych, co obecny maksymalny wynik.
Na końcu funkcja zwraca dwie wartości: największą liczbę przełożonych oraz liczbę pracowników, którzy mają dokładnie tylu przełożonych. Wynik zostaje następnie wypisany na ekranie.
Alternatywne rozwiązanie – wersja rekurencyjna
Alternatywnie funkcję liczącą liczbę przełożonych można było zaimplementować rekurencyjnie.
Funkcja licz_przelozonych działa bardzo podobnie do wersji z pętlą. Dla danego pracownika sprawdzamy, czy dotarliśmy już do szefa firmy. W tym rozwiązaniu zakładamy, że szefem jest pracownik o numerze 1, dlatego jeśli nr_pracownika == 1, zwracamy 0, ponieważ szef nie ma żadnych przełożonych.
W przeciwnym przypadku pracownik ma przełożonego, więc doliczamy 1 za jego bezpośredniego przełożonego, a następnie rekurencyjnie wywołujemy funkcję dla tego przełożonego. Funkcja przechodzi coraz wyżej w strukturze firmy – od pracownika do jego przełożonego, potem do przełożonego tego przełożonego i tak dalej – aż dotrze do szefa. Po dotarciu do szefa rekurencja zaczyna się zwijać, a kolejne jedynki są sumowane. W ten sposób otrzymujemy całkowitą liczbę przełożonych danego pracownika.
Odpowiedź: 22 2 (największa liczba przełożonych: 22, liczba pracowników, którzy mają 22 przełożonych: 2).
Finalne wyniki zapisane w pliku wyniki4.txt prezentują się następująco.

Zadanie 5: Wyrażenie matematyczne (systemy liczbowe) – Matura z Informatyki 2026

Jest to standardowe zadanie z systemów liczbowych, w którym wykorzystujemy dodawanie i odejmowanie liczb w różnych systemach: piątkowym, trójkowym i dziesiętnym. Aby znaleźć brakujące liczby, zaczynamy od podzielenia wskazanego równania na dwa osobne wyrażenia. Pierwsze w systemie piątkowym i dziesiętnym: 1440₅ + ……₅ = 427₁₀ oraz drugie w systemie dziesiętnym i trójkowym: 427₁₀ = …..₃ − 110002₃.
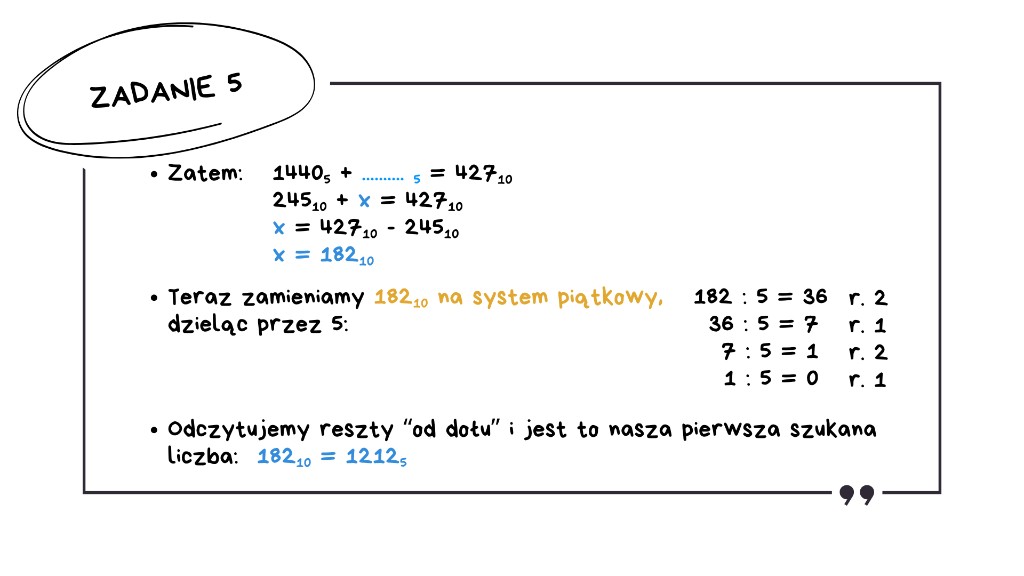
Skupmy się najpierw na pierwszym wyrażeniu: 1440₅ + ……₅ = 427₁₀.
Szukamy liczby w systemie piątkowym, którą należy dodać do liczby 1440₅, aby otrzymać 427₁₀. Chcemy stworzyć proste równanie z jedną niewiadomą w systemie dziesiętnym, a następnie zamienimy otrzymaną liczbę na system piątkowy.
Zamieniamy liczbę 1440₅ na system dziesiętny, czyli każdą cyfrę przemnażamy przez piątkę podniesioną do odpowiedniej potęgi.

Skoro 1440₅ wynosi 245₁₀, traktujemy nasze wyrażenie jak równanie matematyczne z jedną niewiadomą: 245₁₀ + x = 427₁₀. Zatem nasza pierwsza szukana liczba wynosi x = 182₁₀.
Ale to nie wszystko, bo w zadaniu mamy wskazane, że ma być to liczba w systemie piątkowym, także teraz zamieniamy 182₁₀ na system piątkowy, dzieląc 182 przez 5. Dla każdego dzielenia zapisujemy resztę i odczytujemy reszty "od dołu". Szukaną liczbą jest 1212₅.
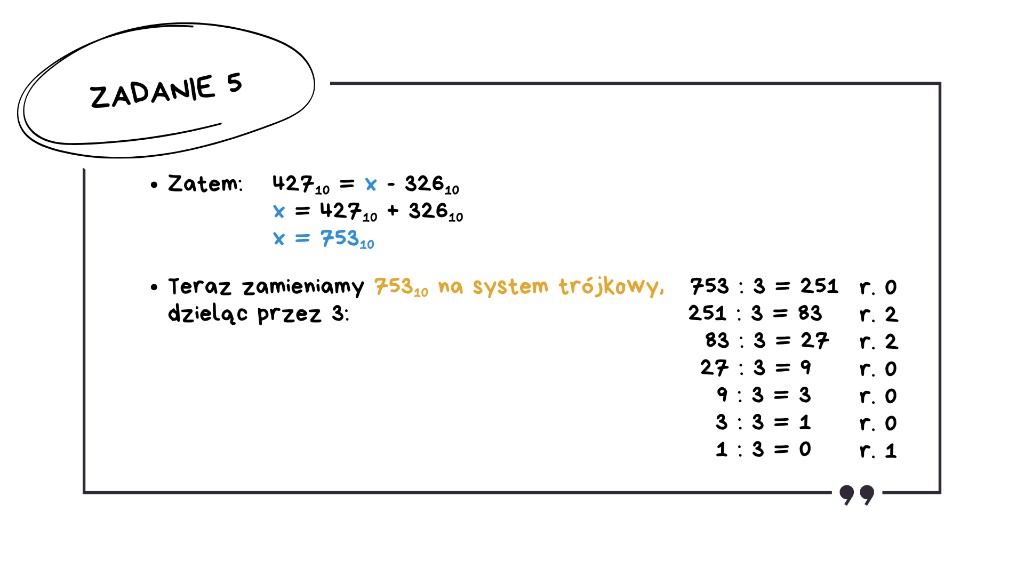
Teraz rozpatrzmy drugie wyrażenie: 427₁₀ = …..₃ − 110002₃.
Szukamy liczby w systemie trójkowym, od której po odjęciu 110002₃ otrzymamy liczbę 427₁₀ (w systemie dziesiętnym). Schemat jest analogiczny jak przy pierwszym wyrażeniu. Tworzymy równanie z jedną niewiadomą w jednym systemie, czyli w systemie dziesiętnym, a następnie otrzymaną liczbę zamieniamy na system trójkowy.
Zamieniamy liczbę 110002₃ na system dziesiętny, czyli analogicznie jak wcześniej, przemnażamy każdą z cyfr, z których składa się liczba 110002 w systemie trójkowym, przez 3, oczywiście podniesioną do odpowiedniej potęgi. Otrzymujemy 326₁₀ (w systemie dziesiętnym).

Otrzymujemy równanie 427₁₀ = x − 326₁₀. Przenosimy 326₁₀ na drugą stronę równania, więc szukaną liczbą w systemie dziesiętnym jest x = 753₁₀.
Teraz zamieniamy 753₁₀ na system trójkowy, czyli 753 dzielimy przez 3 tak długo, aż dojdziemy do zera. Do każdego dzielenia zapisujemy resztę i odczytujemy je "od dołu" i jest to nasza druga szukana liczba: 753₁₀ = 1000220₃.
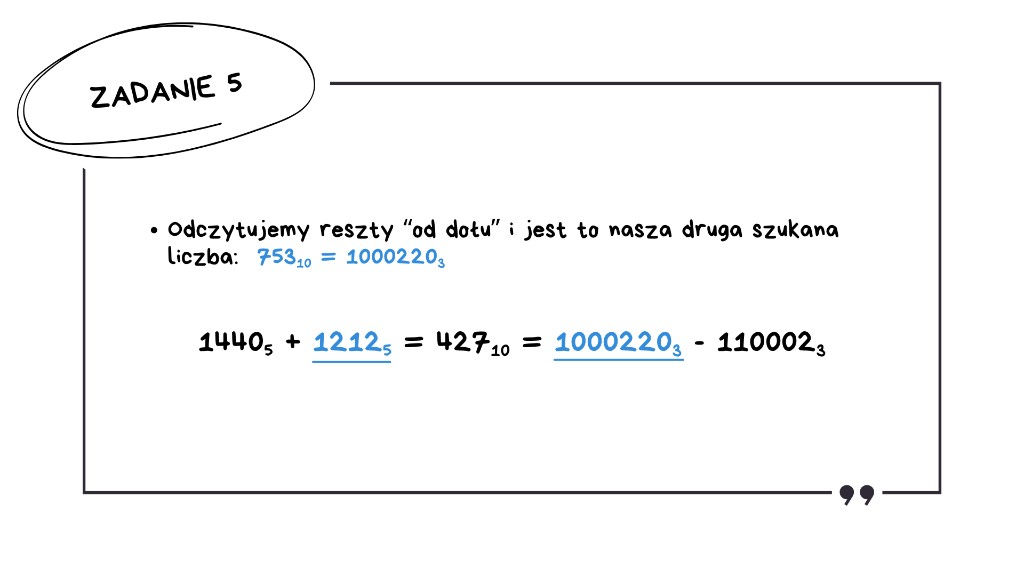

Drugim, zdecydowanie szybszym sposobem na rozwiązanie tego zadania byłoby użycie języka programowania – za pomocą odpowiednich funkcji wbudowanych otrzymalibyśmy gotowy wynik praktycznie od ręki. Warto jednak znać oba podejścia, co dobitnie pokazał arkusz maturalny 2025, gdzie w liczbach pojawiały się puste pola i dodawanie pisemne trzeba było wykonać samodzielnie, bez wsparcia funkcji wbudowanych.
Zadanie 6: Długości adresów IP – Matura z Informatyki 2026

Jest to zadanie z teorii informatyki, które pojawia się w każdym arkuszu maturalnym – zazwyczaj za 1 punkt, czyli 2% ostatecznego wyniku. Niemniej jednak o każdy punkt warto walczyć.
Odpowiedź można było znać z nauki teorii albo po prostu wywnioskować.
Sposób pierwszy – wnioskowanie
Zacznijmy od wnioskowania.

Wiemy, że adres IPv4 zapisujemy jako cztery liczby oddzielone kropkami, na przykład 192.168.0.1. Każda z tych liczb to jeden oktet, a największa wartość w oktecie to 255. Liczba 255 w systemie binarnym to osiem jedynek,

a każda jedynka zajmuje jeden bit – mamy zatem 8 bitów na oktet. Cztery oktety razy 8 bitów daje nam 32 bity na adres IPv4.
Analogicznie podchodzimy do IPv6 – tylko tam mamy osiem grup znaków oddzielonych dwukropkami.

Każda grupa składa się z czterech cyfr szesnastkowych, na przykład FFFF. Największa wartość w grupie, czyli FFFF w systemie szesnastkowym,


po przełożeniu na binarny daje 16 jedynek, czyli 16 bitów. Osiem grup razy 16 bitów daje nam 128 bitów na adres IPv6.

Sposób drugi – zapamiętanie
Drugą opcją było po prostu zapamiętanie tych wartości, bo 32 bity dla IPv4 i 128 bitów dla IPv6 to cechy charakterystyczne tych protokołów.
Gdzie można było znaleźć tę informację?

Można też było znaleźć odpowiedź w naszej książce Matura Informatyka — Teoria, gdzie na stronie 101 wprost wyjaśniliśmy, że IPv4 wykorzystuje 32-bitowy adres, a IPv6 adres 128-bitowy.
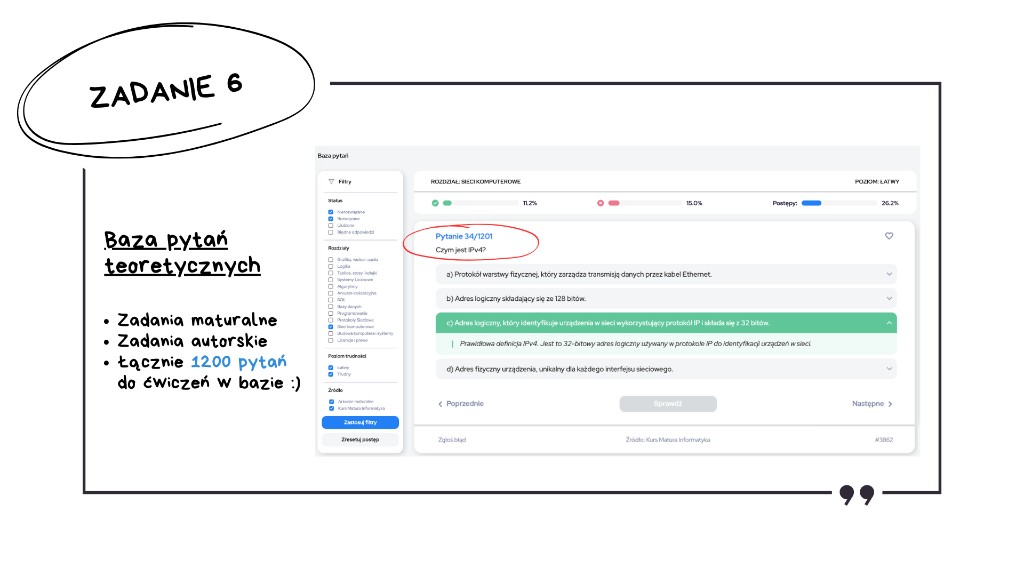
A także takie właśnie pytania znajdowały się w naszej bazie pytań testowych.
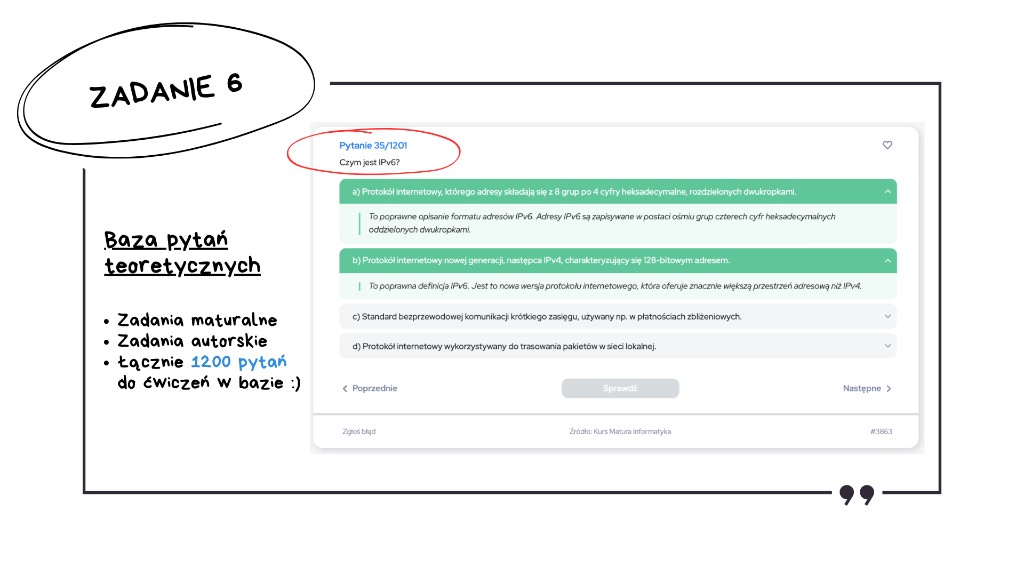
Kto czytał książkę lub ćwiczył pytania z bazy pytań, z pewnością odpowiedział na to pytanie bez żadnego zastanowienia.
W ramach dodatkowego wsparcia w procesie nauki, przygotowaliśmy dla Ciebie książkę „MATURA INFORMATYKA - TEORIA”.
Materiały zostały stworzone z myślą o zróżnicowanych stylach nauki – zarówno w formie czytanej, jak i słuchanej – aby ułatwić przyswajanie wiedzy i zwiększyć efektywność Twojej nauki.

Zadanie 7: Staw – Matura z Informatyki 2026

Szybki rzut oka na dane. W pliku staw.txt mamy datę, temperaturę oraz opady z całego 2022 roku.
Zadanie 7.1: Wykres kolumnowy – średnie miesięczne temperatury

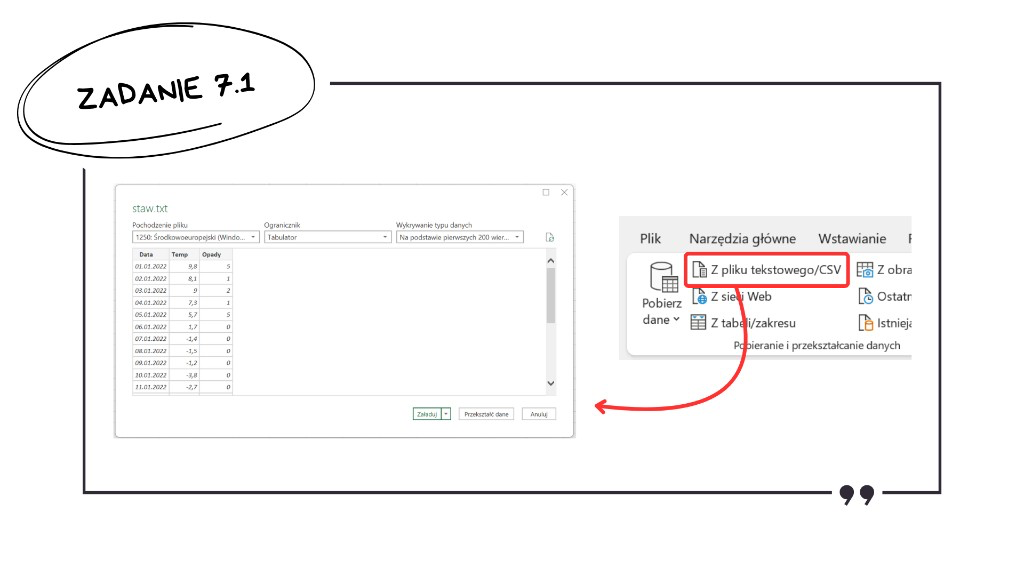
Jak każde zadanie z Excela rozpoczynamy od wczytania danych. Wchodzimy w zakładkę „Dane” i wybieramy „Z pliku tekstowego/CSV”. Excel powinien sam rozpoznać odpowiedni format, ale warto upewnić się, że ogranicznikiem jest tabulator, a daty są poprawnie wykryte. Klikamy „Załaduj” i mamy bazę do pracy.
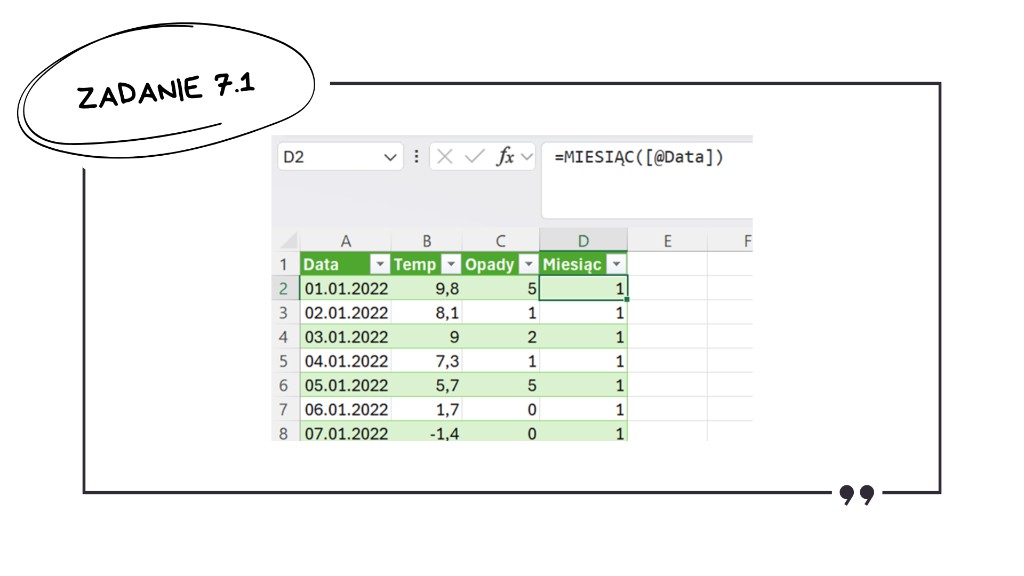
Aby utworzyć zestawienie miesięczne, musimy najpierw wyciągnąć miesiąc z daty. Użyjemy do tego prostej funkcji MIESIĄC() z naszą datą jako parametr.
Teraz czas na główne obliczenia. Na szczęście Excel ma zaawansowaną funkcję ŚREDNIA.WARUNKÓW(). Dzięki niej nie musimy pisać zagnieżdżonych funkcji JEŻELI() – wystarczy wskazać trzy elementy: z czego liczymy średnią, gdzie szukamy warunku i jaki to konkretnie warunek.

Jako pierwszy argument podajemy zakres temperatur, z których liczymy średnią. Drugi to nasza nowa kolumna z miesiącami, a trzeci to konkretny numer miesiąca, dla którego w danym wierszu robimy obliczenie. Pamiętajmy też o zaokrągleniu w formule do jednego miejsca po przecinku.
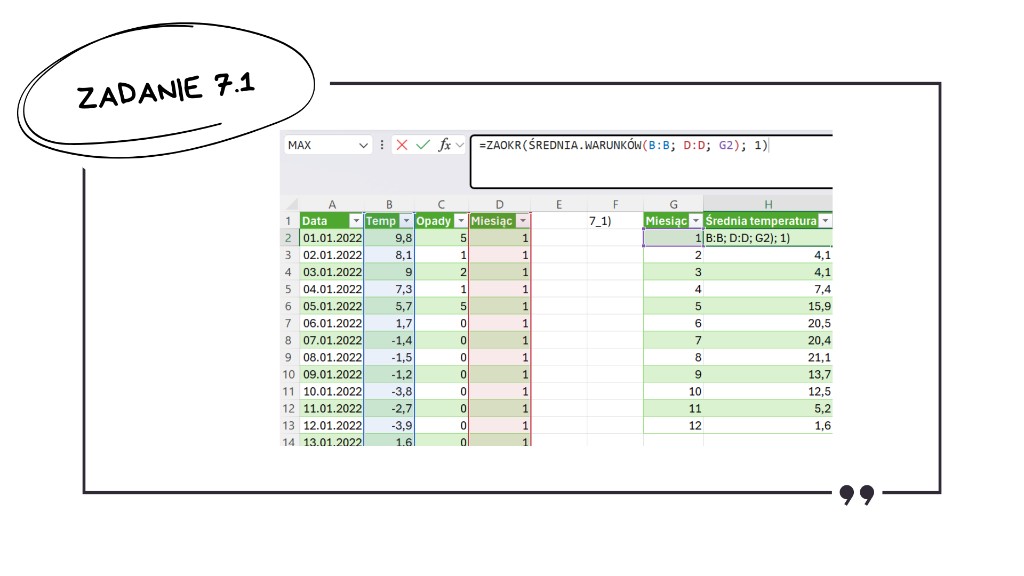
Gdy zestawienie jest gotowe, zaznaczamy naszą tabelę, wchodzimy w zakładkę „Wstawianie” i w sekcji z wykresami wybieramy klasyczny wykres kolumnowy 2D.
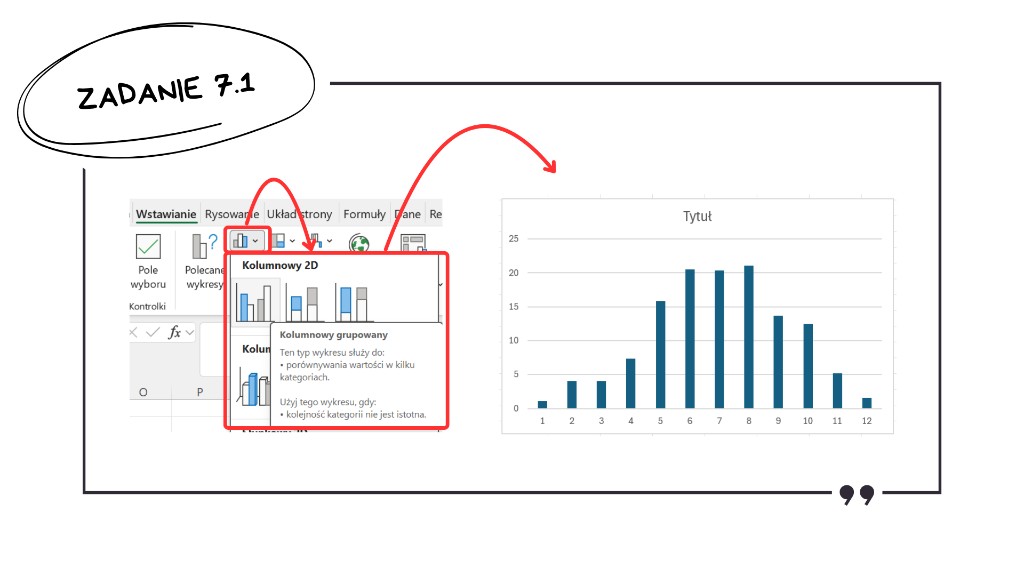
Uwaga! Samo wstawienie wykresu to dopiero połowa sukcesu. Wytyczne w kluczu CKE wskazują wprost, że egzaminator nie może przyznać maksymalnej liczby punktów za zadanie z wykresem, jeśli brakuje odpowiedniego formatowania. Zadbaj o czytelne formatowanie, czyli dodaj odpowiedni tytuł wskazany w zadaniu, opisy osi oraz legendę (jeśli jest wymagana). Brak tych elementów to częsty błąd, który prowadzi do niepotrzebnej straty punktów.
Co też ciekawe, nawet jeśli dane przedstawione na wykresie byłyby niepoprawne, a formatowanie wykresu będzie dobrze zrobione, otrzymasz punkty właśnie za formatowanie wykresu.
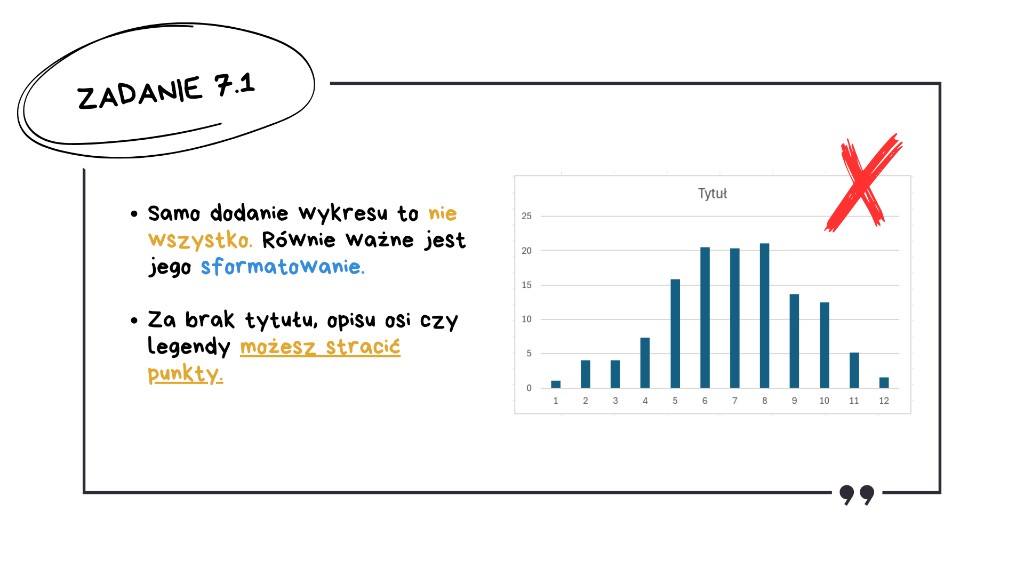
Jak to zrobić szybko i sprawnie? Zielony plusik w prawym górnym rogu wykresu pozwoli wybrać jego elementy. W tym zadaniu potrzebujemy tytuły osi i wykresu oraz etykiety danych.
Zmiana etykiet osi jest trochę bardziej wymagająca. Najpierw trzeba utworzyć je w osobnej kolumnie, a następnie w zakładce „Projekt wykresu” wybrać „Zaznacz dane”. Klikamy „Edytuj” i w okienku po prawej stronie zaznaczamy kolumnę z nazwami miesięcy.
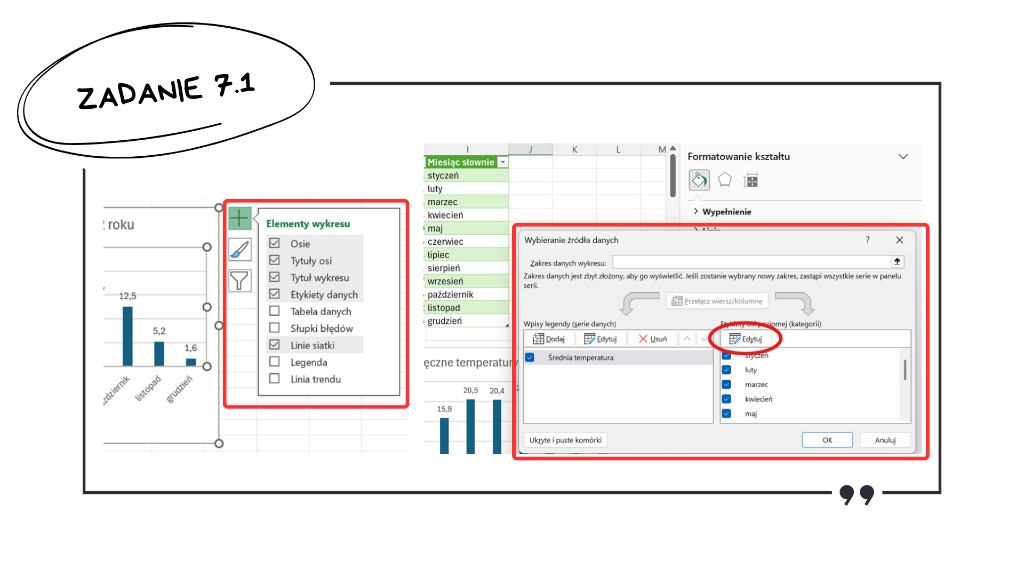
Tak przygotowany wykres zapewni Ci maksymalną liczbę punktów za to zadanie.
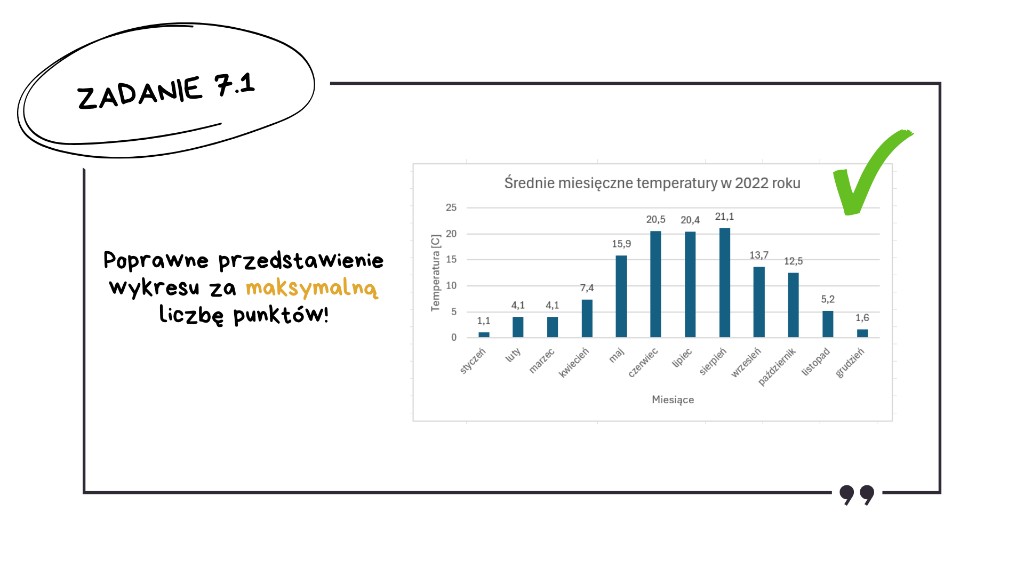
Zadanie 7.2: Najdłuższy ciąg kolejnych dni bez opadów

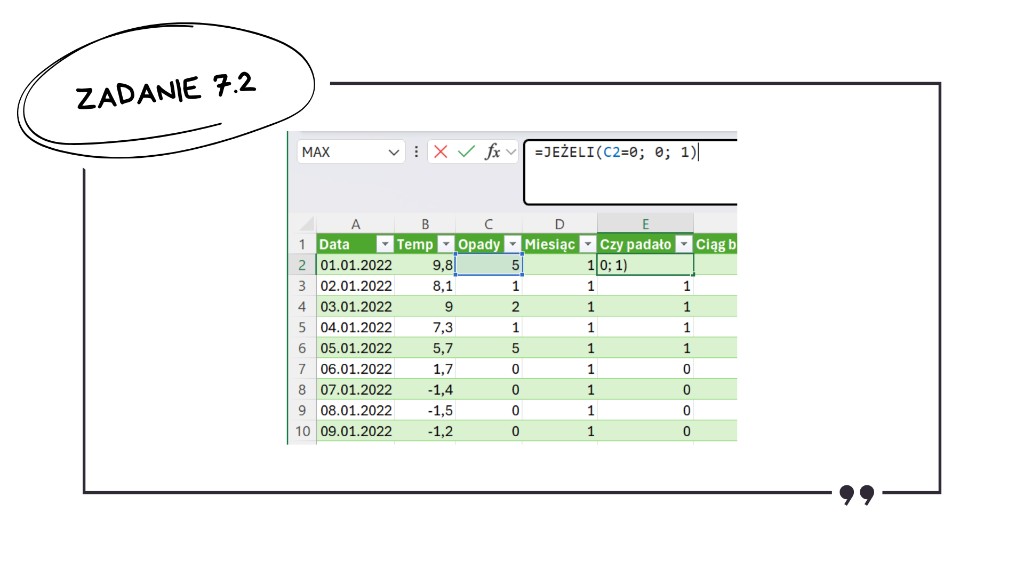
Zadanie wymaga od nas trochę więcej logiki niż poprzednie. Musimy policzyć spójne podciągi, ale z jednym ważnym zastrzeżeniem – licznik musi się resetować nie tylko wtedy, gdy spadnie deszcz, ale również wtedy, gdy zmieni się miesiąc.
Rozwiązanie warto zacząć od kolumny pomocniczej „Czy padało?”. Używamy tu prostej funkcji JEŻELI(), która sprawdzi, czy wartość w kolumnie „Opady” jest równa 0. Jeśli tak – funkcja zwróci 0, co oznacza brak opadów. W przeciwnym wypadku otrzymamy 1, czyli potwierdzenie, że tego dnia padało.
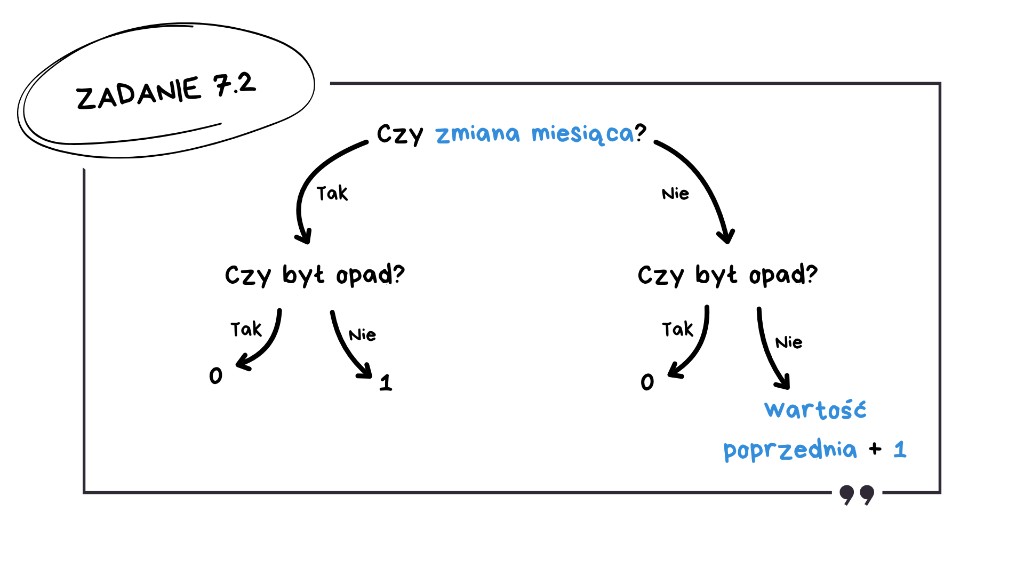
Zanim przejdziemy do pisania głównej formuły na długość ciągu, spójrzmy na schemat logiczny. Musimy sprawdzić dwa kluczowe warunki: czy zmienił się miesiąc oraz czy w ogóle padało. Jeśli miesiąc jest nowy, sprawdzamy tylko bieżący dzień. Jeśli jednak jesteśmy w tym samym miesiącu, sprawdzamy, czy możemy wydłużyć wczorajszą passę bez deszczu o 1, czy musimy zresetować licznik do zera z powodu opadów.
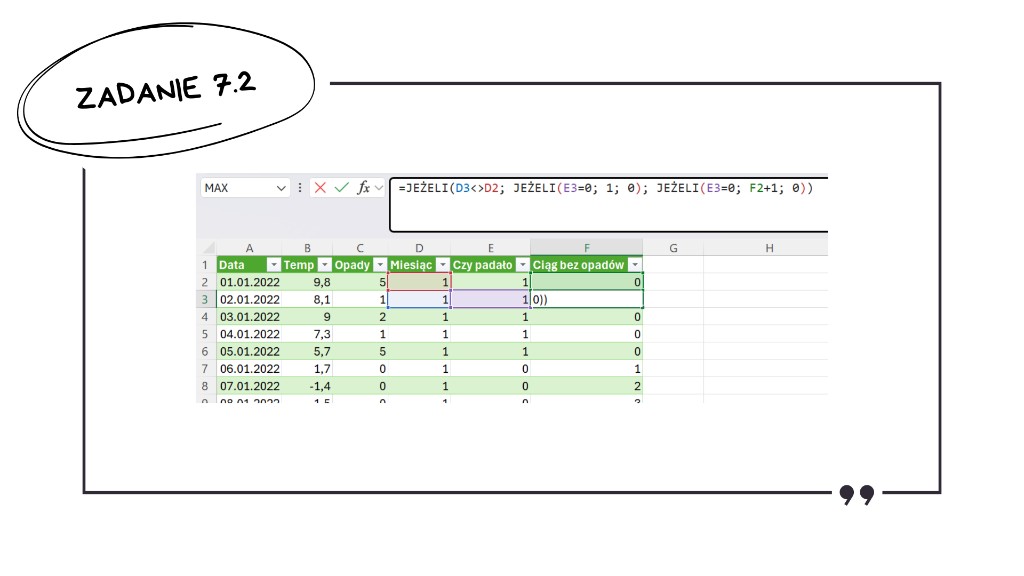
W praktyce realizujemy to za pomocą zagnieżdżonej funkcji =JEŻELI(). Najpierw sprawdzamy zmianę miesiąca. Jeśli miesiąc się zmienił, sprawdzamy czy padało. Jeżeli nie, startujemy od 1. Jeśli tak – od 0. Natomiast jeżeli to ten sam miesiąc, sprawdzamy naszą kolumnę pomocniczą i gdy mamy tam 0, do wyniku z poprzedniego dnia dodajemy 1. W przeciwnym wypadku zostawiamy 0.
Mając tak przygotowaną kolumnę z ciągami, wystarczy wyciągnąć wartość maksymalną dla każdego miesiąca. Ponownie z pomocą przychodzi funkcja warunkowa – tym razem MAKS.WARUNKÓW(). Jako zakres wyszukiwania podajemy nasze wyliczone ciągi, jako kryterium – zakres z miesiącami, a jako wartość warunku – numer badanego miesiąca.
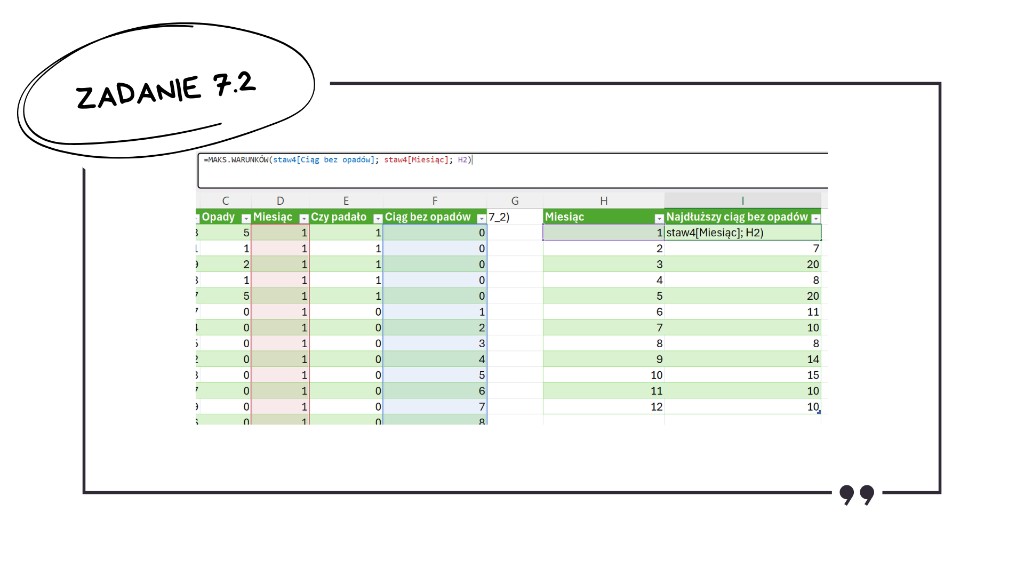

Informacja do zadań 7.3–7.4
Przechodzimy do najciekawszej części tegorocznego Excela – symulacji.

Zadanie 7.3: Symulacja – dzień przekroczenia 75% powierzchni stawu

Budowę symulacji zaczynamy od wygenerowania osi czasu. Wpisujemy datę początkową 01.03.2023 w komórkę A2 i przeciągamy ją w dół. Aby objąć cały badany okres 184 dni, musimy dojechać aż do komórki A185 – Excel automatycznie uzupełni daty pomiędzy.
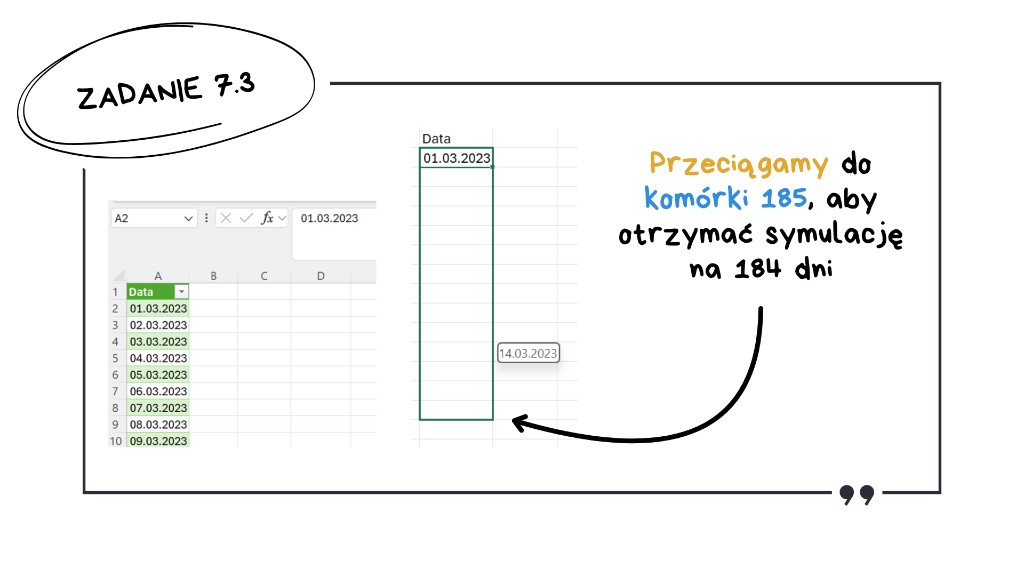
Bardzo pomocna będzie kolumna z dniem tygodnia. Dlaczego? Bo właściciel odławia rzęsę tylko w piątki. Używamy funkcji DZIEŃ.TYG(). Parametr 2 jest tu bardzo ważny – dzięki niemu poniedziałek to 1, a nasz kluczowy piątek to 5. To znacznie ułatwi pisanie warunku ubytku.

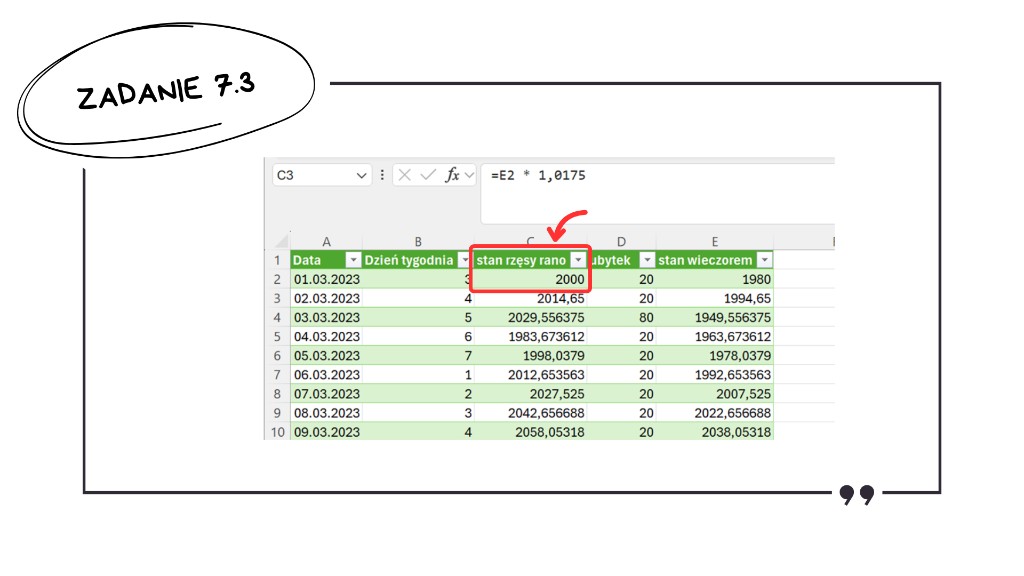
Przechodzimy do liczenia powierzchni zarośnięcia stawu przez rzęsę. Z treści zadania wiemy, że 1 marca rano staw był zarośnięty w 20%, czyli 20% z 10 000 m² równa się 2000 m². Na razie zostawiamy stan rano, ponieważ zależy on od reszty symulacji.
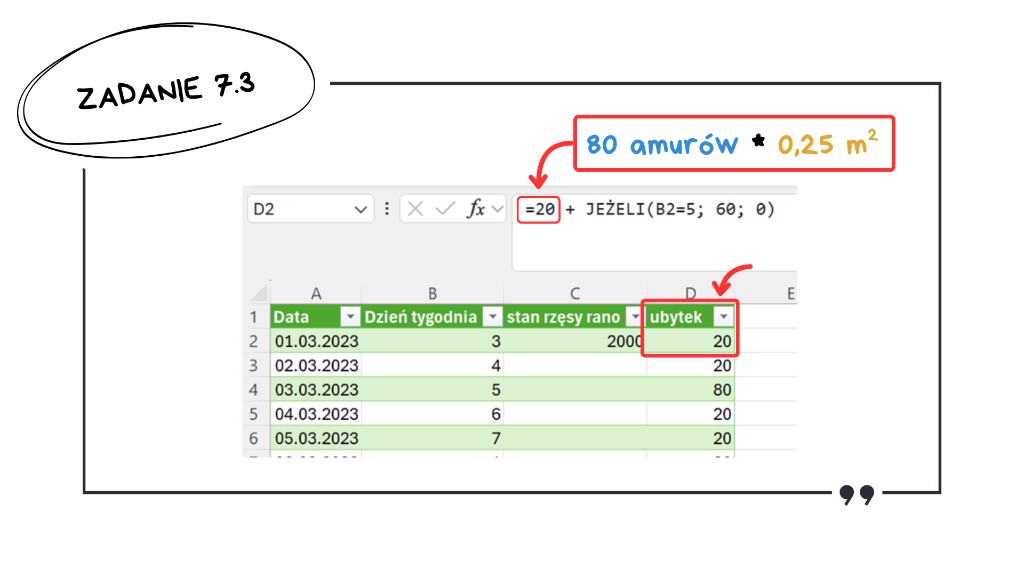
Sercem naszego modelu będzie formuła na ubytek rzęsy w ciągu dnia. Wiemy, że 80 amurów zjada łącznie 20 m² (80 razy wydajność jednego amura, czyli 0,25 m²). Do tego dochodzą piątkowe odłowienia właściciela. Jeśli w kolumnie z dniem tygodnia mamy piątkę, Excel odejmie łącznie 80 m², w pozostałe dni tylko 20 m².
Stan wieczorem to po prostu różnica stanu z rana i ubytku, który właśnie wyliczyliśmy.
Teraz musimy wrócić do stanu rano kolejnego dnia. Co działo się w nocy? Rzęsa rosła. Stan rano to wczorajszy stan wieczorem pomnożony przez współczynnik wzrostu. Skoro przyrost wynosi 1,75%, to mnożymy przez 1,0175. Pamiętajmy, by tę formułę wpisać dopiero od kolejnego wiersza (czyli 2 marca), bo 1 marca mamy podaną wartość startową 2000 m².
![Rozwiązanie zadania 7.3 — Excel: kolumna stan wieczorem obliczana jako różnica stanu rano i ubytku (formuła =[@[stan rzęsy rano]]-[@ubytek])](/images/_blog/wyniki-matura-informatyka-2026-zadanie-7-3-excel-stan-wieczorem-rano-minus-ubytek.png)
Ostatni element to przeliczenie powierzchni na procenty. Dzielimy aktualny stan rano przez całkowitą powierzchnię stawu, czyli przez 10 000. Formatujemy komórkę jako procentową i możemy przystąpić do sprawdzania wyników.
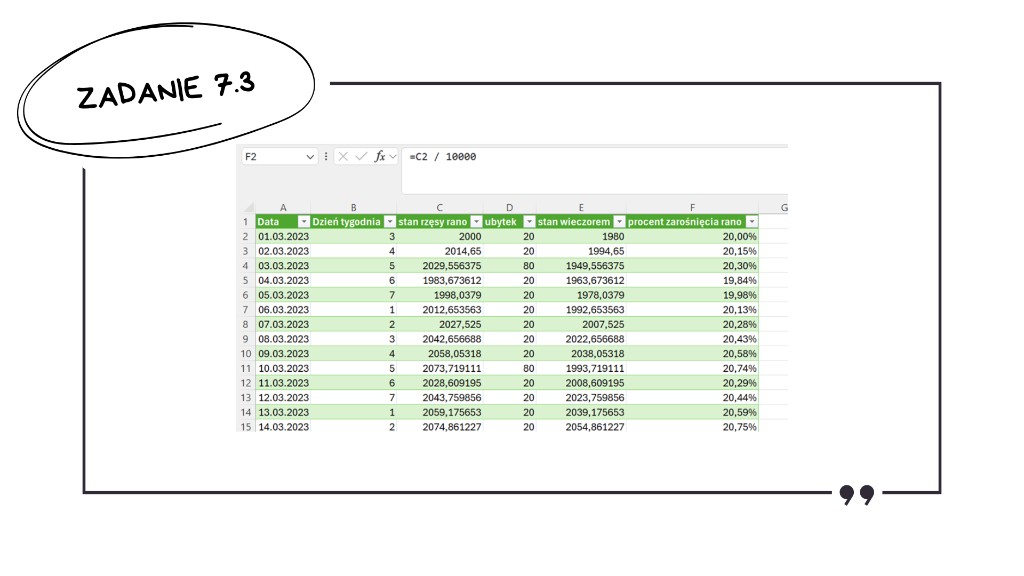
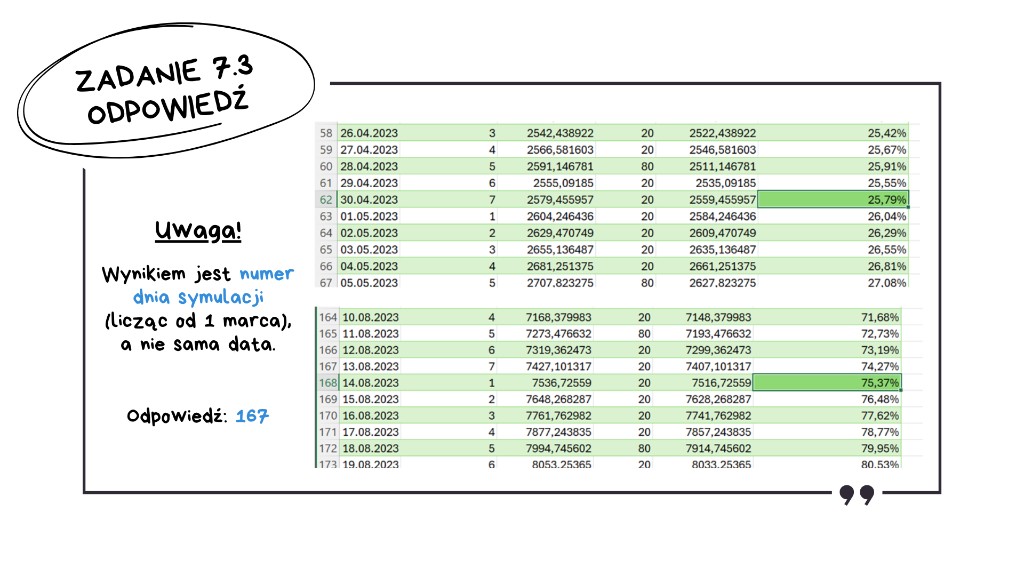
Szybka weryfikacja ze wskazówką w treści zadania: 30 kwietnia rano mamy 25,79% – idealnie, nasz model działa bezbłędnie. Teraz szukamy momentu, w którym wartość przekracza 75%. Dzieje się to 14 sierpnia 2023 roku.
Ale uwaga! Data nie jest naszą finalną odpowiedzią – w zadaniu oczekują informacji, który to dzień symulacji z kolei. U nas to wiersz 168, czyli odejmując pierwszy wiersz nagłówków – 167 dzień symulacji. Zapisujemy wyniki do pliku i mamy kolejne punkty.
Zadanie 7.4: Symulacja – dodanie amurów do stawu
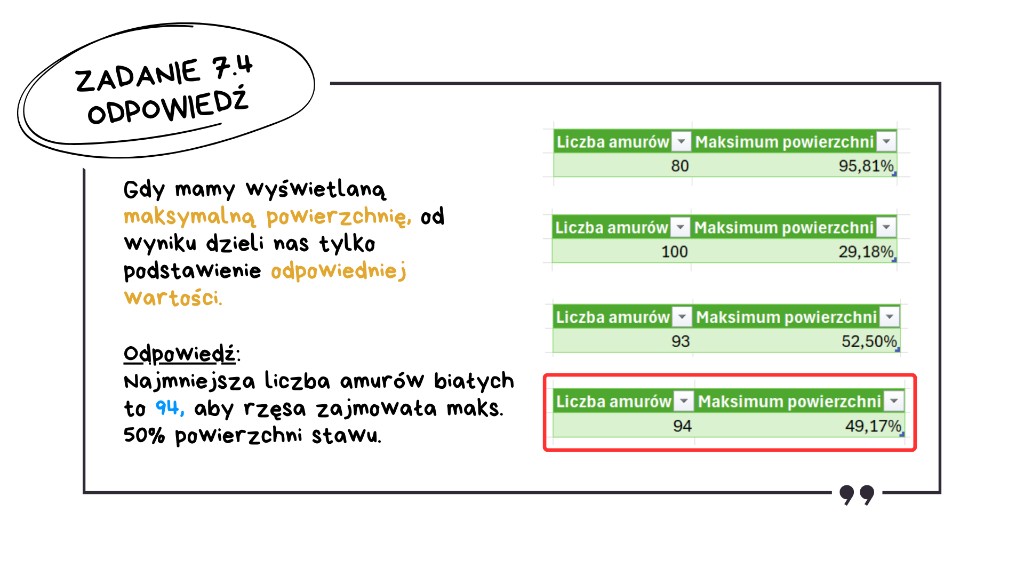
Z przygotowanymi formułami z poprzedniego podpunktu to zadanie to formalność. Wystarczy manipulować liczbą amurów w naszej formule z ubytkiem i sprawdzać wartość maksymalną powierzchni rzęsy. Zmodyfikujmy formułę liczącą ubytek tak, aby liczba amurów była pobierana z konkretnej, pojedynczej komórki – dzięki temu w ułamek sekundy zmieniamy kolejne warianty.
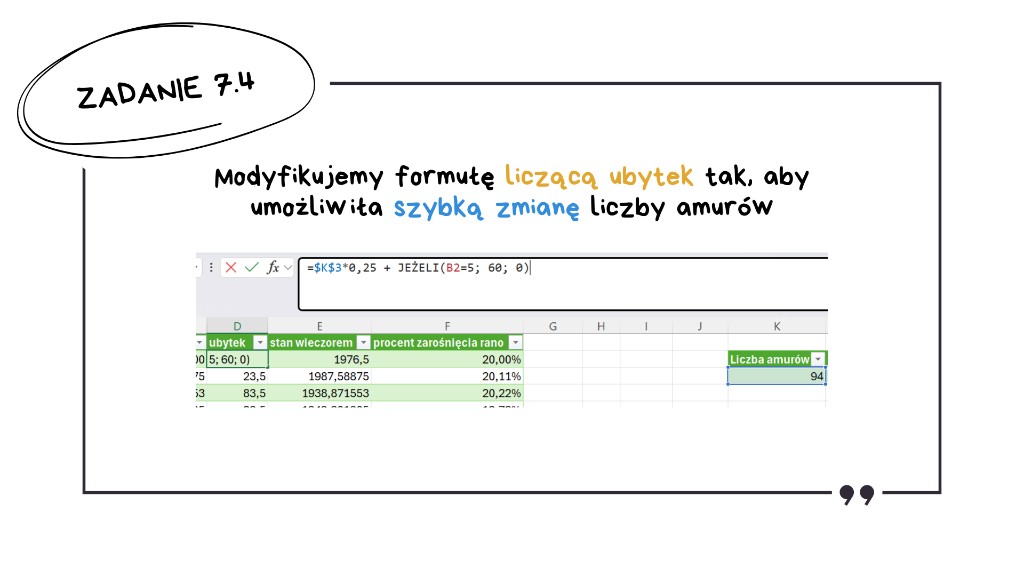
Zanim zaczniemy testować różne wartości, dopiszmy jeszcze formułę, która szybko sprawdzi najwyższy zanotowany procent zarośnięcia w całym badanym okresie. Teraz zostaje już tylko podstawienie liczby, która sprawi, że MAKS() zwróci mniej niż 50%, ale po zmniejszeniu o jeden otrzymamy wartość przekraczającą limit:
- 80 amurów → zarośnięcie dobija do 96%,
- 100 amurów → zarośnięcie spada poniżej 30%,
- 93 amury → wciąż jeszcze 52,50%,
- 94 amury → 49,17% – zmniejszenie liczby amurów wyprowadza nas już poza limit 50%.
Na końcu możemy jeszcze rzucić okiem, jak wyglądałby wypełniony plik wyniki7.txt z odpowiedziami do zadania. I gotowe! Wszystkie zadania dotyczące arkusza kalkulacyjnego mamy wykonane. :)

Zadanie 8: Sieć sklepów – Matura z Informatyki 2026

Zadanie należało zacząć od wczytania danych z plików tekstowych dołączonych do arkusza. Są to trzy zbiory rekordów: klienci.txt, transakcje.txt oraz opis_transakcji.txt — zwykle każdy importujemy do osobnej tabeli (np. Klienci, Transakcje, Opis_transakcji).
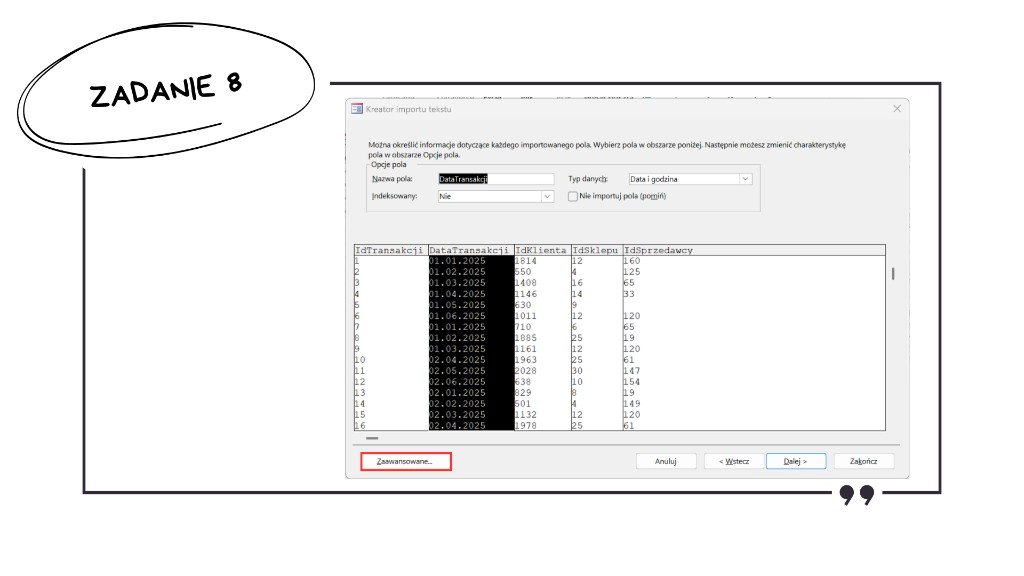
- Uwaga 1 (data w transakcjach). Przy imporcie
transakcje.txtwarto upewnić się, że pole z datą ma właściwy typ (Data i godzina) oraz że daty są odczytywane w układzie DMR (dzień–miesiąc–rok), zgodnie z arkuszem. W większości przypadków Access ustawi to poprawnie w kreatorze, ale ten krok warto zweryfikować przy pierwszym imporcie (także w zapisanej specyfikacji). - Uwaga 2 (
opis_transakcji). W tej tabeli poleIdTransakcjipowtarza się (wiele wierszy na jedną transakcję), więc nie nadaje się na klucz podstawowy — przy imporcie nie wolno zakładać, że jest unikalne między wierszamiOpis_transakcji.
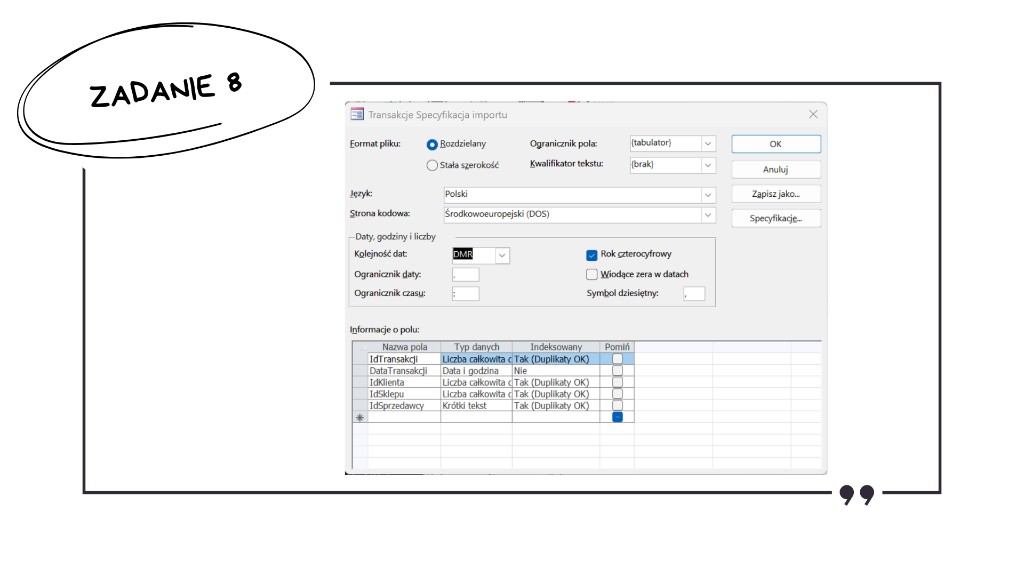
Po wczytaniu danych trzeba było jeszcze powiązać tabele relacjami zgodnie ze schematem z arkusza: między innymi Klienci → Transakcje po IdKlienta oraz Transakcje → Opis_transakcji po IdTransakcji (typowe powiązania jeden-do-wielu). Poniżej przykład takiego układu w oknie relacji Access.
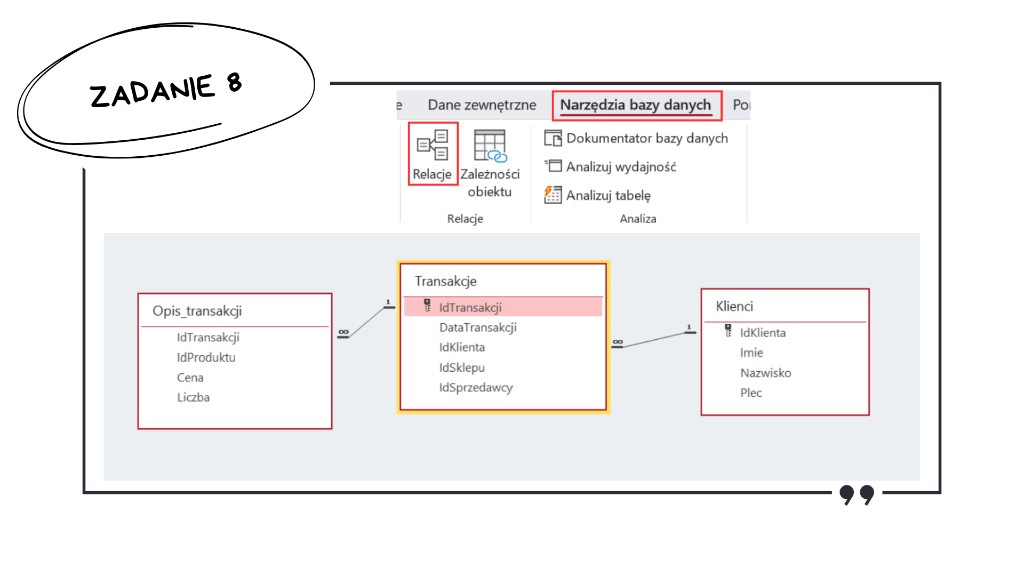
Zadanie 8.1: Klient z największą liczbą transakcji

W zadaniu należy znaleźć imię i nazwisko klienta, który w rozpatrywanym okresie zrealizował łącznie najwięcej transakcji — czyli takiego, dla kogo w tabeli Transakcje jest najwięcej wierszy (największa liczba IdTransakcji przypiętych do danego IdKlienta). Wystarczą tu dwie tabele: Klienci i Transakcje (powiązane po IdKlienta), żeby złączyć dane biograficzne z liczbą zapisów o zakupach.
W kwerendzie stosujemy Grupuj według m.in. po IdKlienta, Imie i Nazwisko, a dla IdTransakcji funkcję Policz — dzięki temu dla każdego klienta dostajemy łączną liczbę transakcji. Następnie ustawiamy sortowanie malejąco według policzonych transakcji i tak dobieramy odpowiedź: interesuje nas pierwszy wiersz (najwyższy licznik).
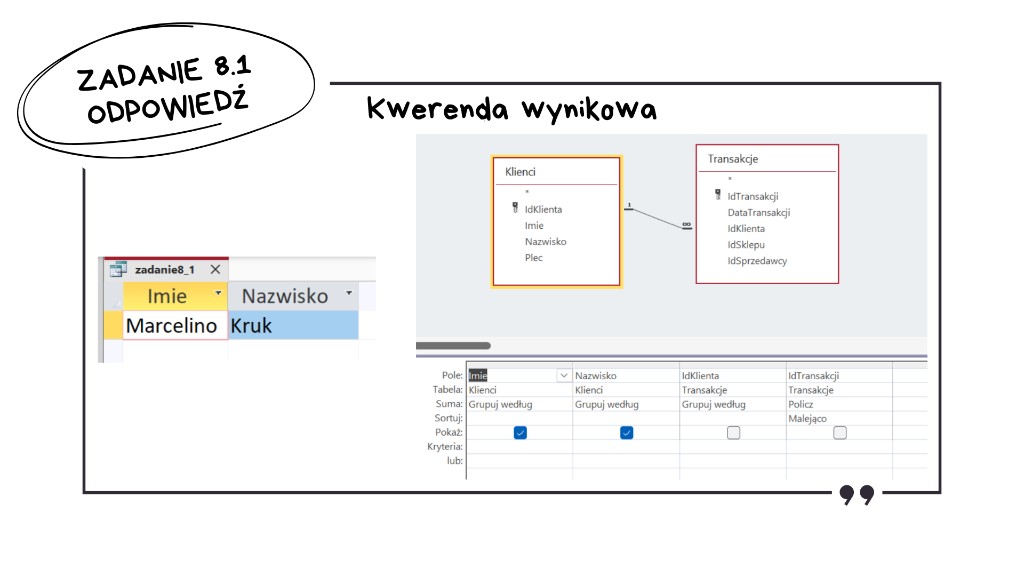
Odpowiedź: Marcelino Kruk
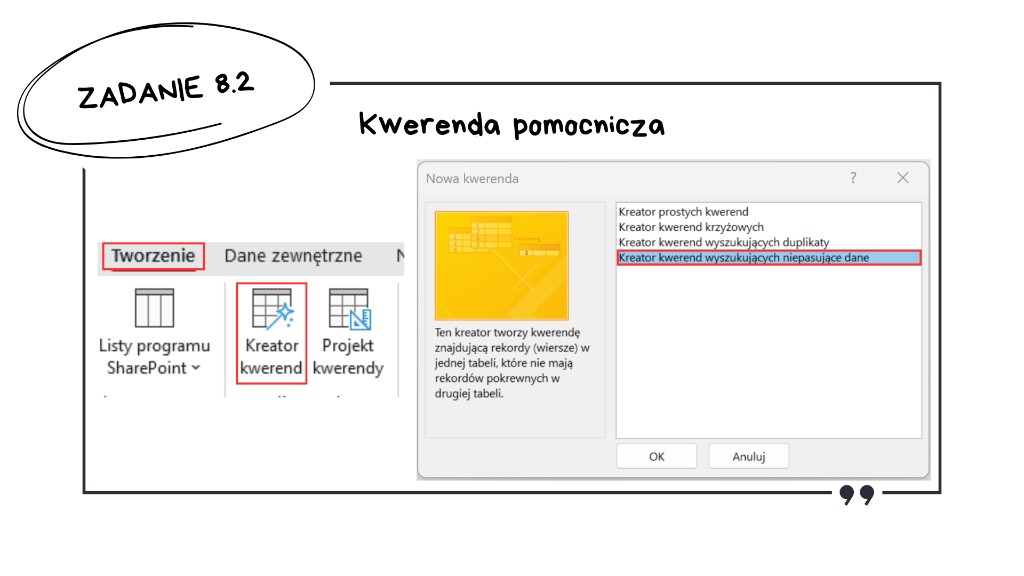
Zadanie 8.2: Klienci, którzy nie kupili niczego (niepasujące dane)

Z technicznego punktu widzenia szukamy identyfikatorów z tabeli Klienci, dla których w tabeli Transakcje nie ma ani jednego wiersza — czyli to naturalne pole do konstrukcji kwerendy wyszukującej niepasujące dane (porównanie Klienci z Transakcje po IdKlienta).
Jak utworzyć kwerendę wyszukującą niepasujące dane?
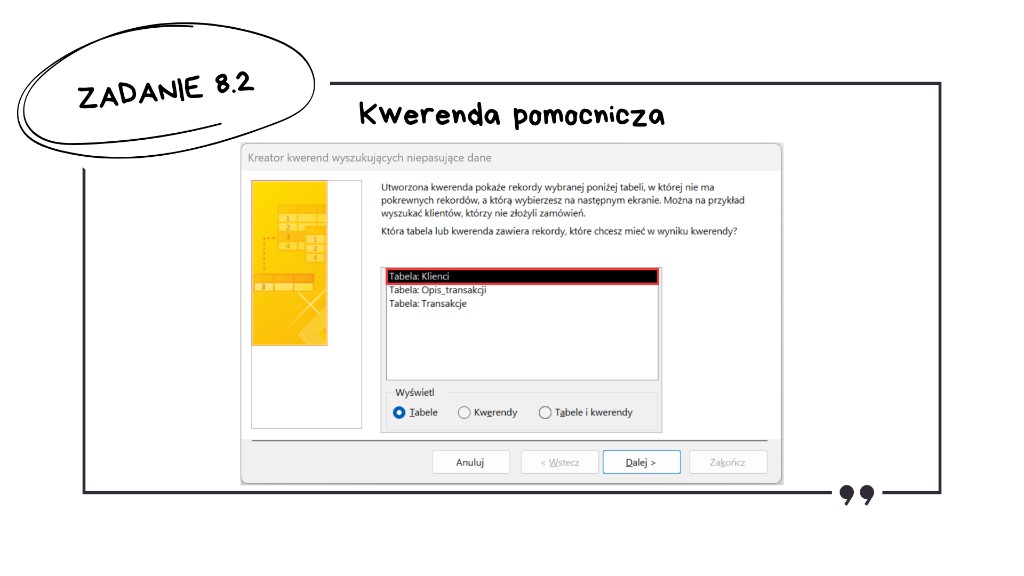
W oknie Nowa kwerenda wybieramy Kreator kwerend wyszukujących niepasujące dane — prowadzi on przez wybór tabeli „źródłowej” i tabeli porównawczej oraz przez dopasowanie klucza.
Interesują nas klienci bez żadnej transakcji — jako pierwszą wskazujemy więc tabelę Klienci: to z niej pochodzą rekordy, które mają trafić do wyniku kwerendy pomocniczej (o ile nie mają dopasowania po drugiej stronie).
Tabelą z pokrewnymi rekordami jest Transakcje — bo to tam szukamy dowodu, że dany klient cokolwiek kupił.
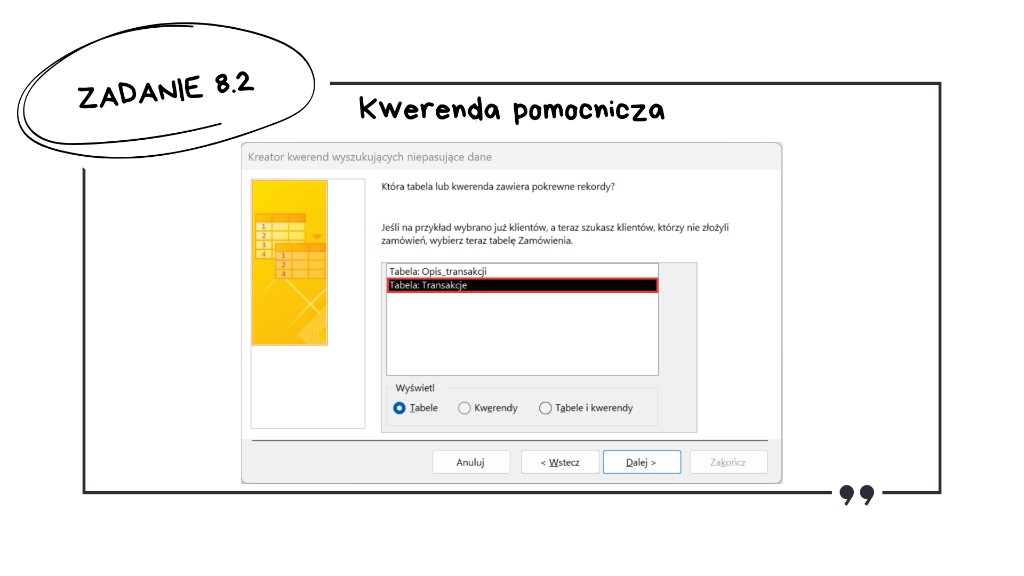
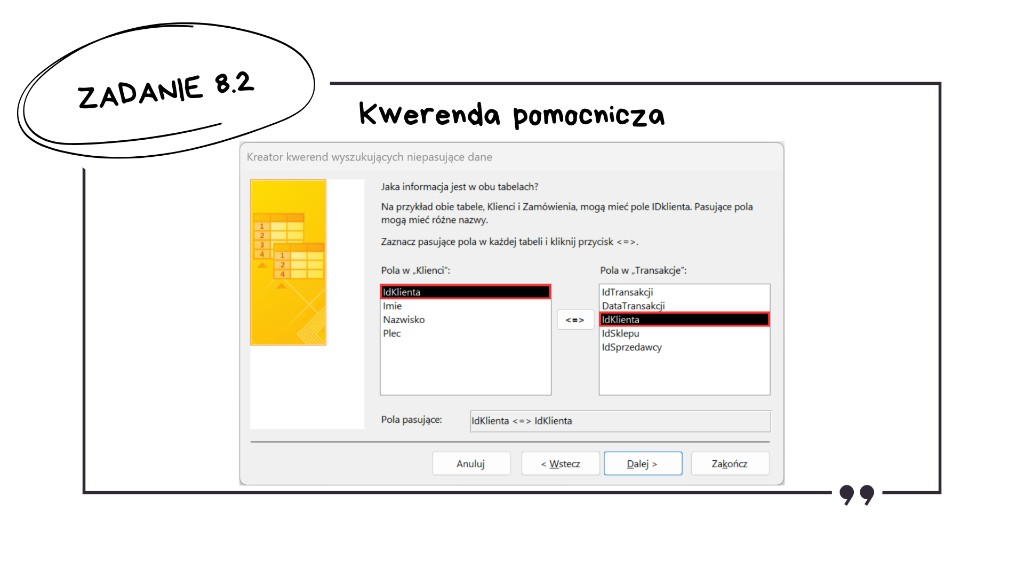
W obu tabelach łączymy się po IdKlienta. W wyniku kreatora chcemy zobaczyć co najmniej IdKlienta oraz Plec, żeby później móc zliczyć łączną liczbę kobiet (K) oraz mężczyzn (M).
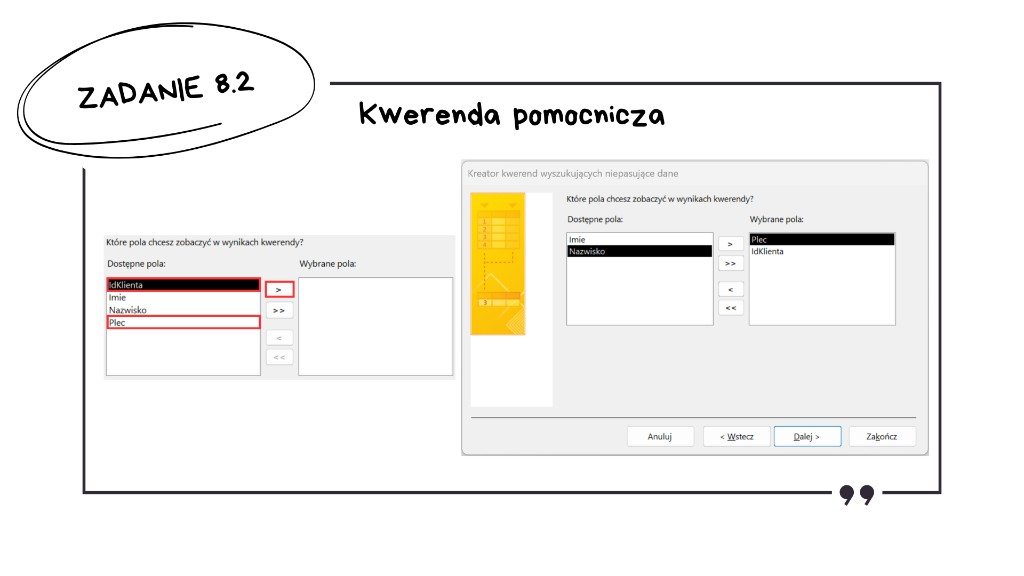
Po zakończeniu kreatora zapisujemy kwerendę pomocniczą — w arkuszu widać listę klientów bez wpisów w Transakcje (np. widok zadanie8_2_pom z polami IdKlienta i Plec).

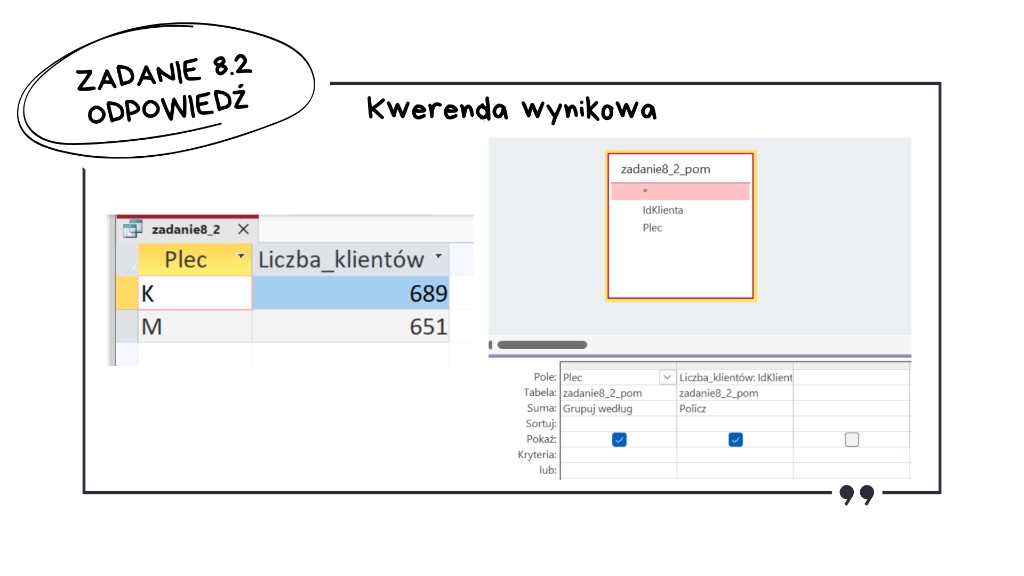
Na podstawie tego zestawienia tworzymy kwerendę wynikową: Grupuj według Plec, a IdKlienta agregujemy przez Policz, żeby otrzymać liczbę kobiet i mężczyzn wśród klientów bez żadnego zakupu.
W arkuszu końcowej kwerendy pojawiają się dwa wiersze z płcią i liczbą osób. Nasza odpowiedź to łączna liczba kobiet (K) czyli 689 oraz łączna liczba mężczyzn (M) czyli 651.
Zadanie 8.3: Liczba sklepów oraz kwota za zakupy w kasach samoobsługowych

Do wyliczenia obu odpowiedzi z polecenia trzeba najpierw wydzielić w bazie transakcje „z kasy samoobsługowej”. Zgodnie z opisem w arkuszu oznacza to brak przypisanego sprzedawcy: w nagłówku tabeli Transakcje pole IdSprzedawcy jest puste, więc w kwerendzie ten przypadek filtrujemy warunkiem Is Null (wartość NULL = brak IdSprzedawcy).
Sensownie jest rozbić pracę na kilka kwerend. Najpierw budujemy kwerendę pomocniczą, która wypisuje unikalne sklepy (IdSklepu), w których w ogóle była transakcja samoobsługowa: łączymy Transakcje z Opis_transakcji (relacja po IdTransakcji), filtrujemy po pustym IdSprzedawcy (Is Null) i przez Grupuj według usuwamy duplikaty sklepów — dokładny układ kolumn w projekcie widać na slajdzie poniżej.

Do odpowiedzi na pierwsze pytanie, czyli o liczbę sklepów, w osobnej kwerendzie wynikowej liczymy rekordy z zestawienia pomocniczego. W przykładzie jest to Policz na IdSklepu względem wcześniej zapisanej listy zadanie8_3_unikalne_sklepy. Otrzymaliśmy wartość 28.
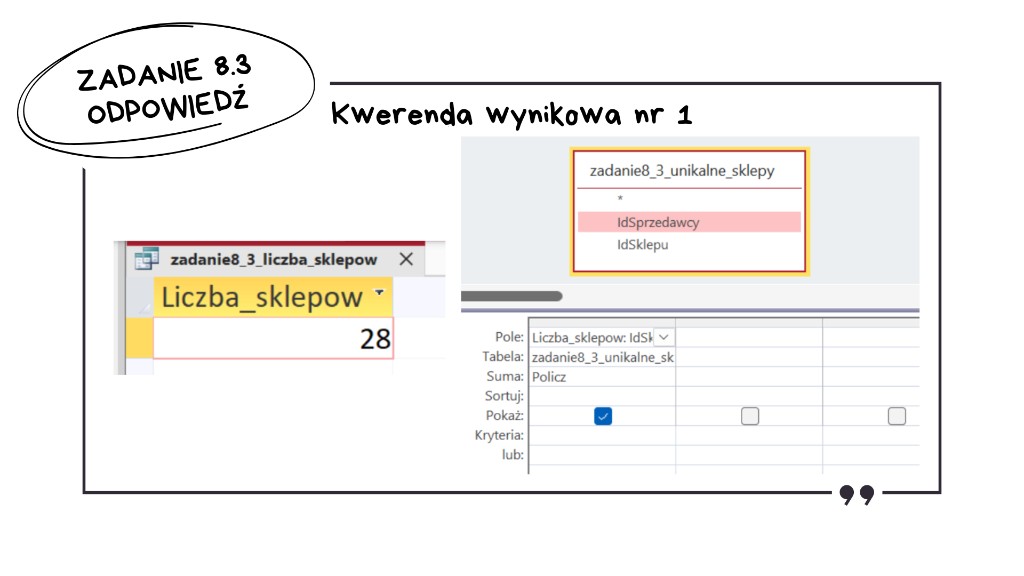
Drugą wartość, czyli łączną zapłatę, liczymy w kolejnej kwerendzie (np. „nr 2”). Znów łączymy Transakcje z Opis_transakcji, ograniczamy się do transakcji z pustym IdSprzedawcy, a kwotę z pozycji zakupu wyprowadzamy jako iloczyn Cena i Liczba. Sumujemy te wartości po wszystkich liniach przypisanych do takich transakcji. Otrzymaliśmy wartość 19443,29.
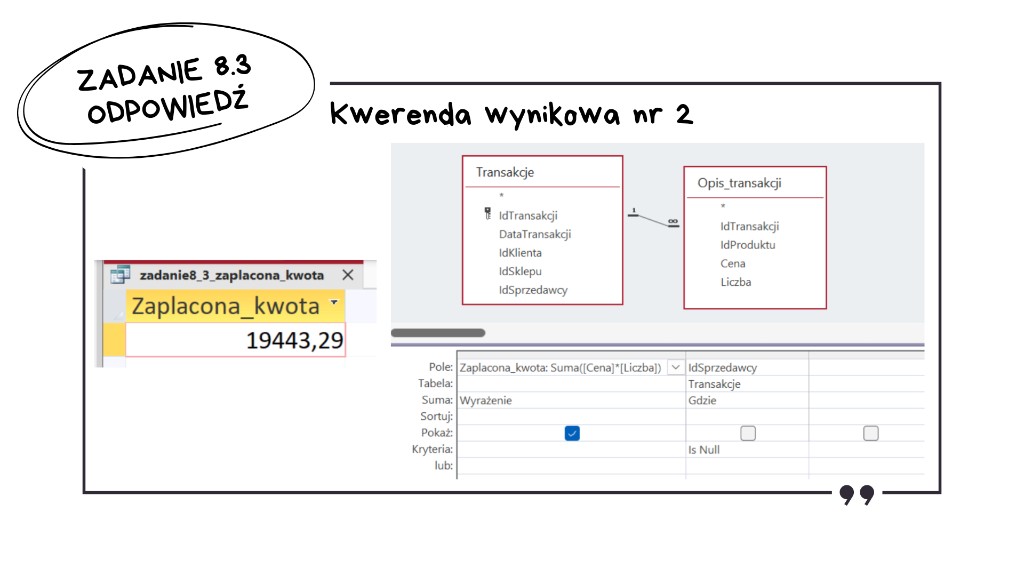
Odpowiedź: liczba różnych sklepów, w których dokonano transakcji w kasach samoobsługowych to 28 oraz zapłacono łącznie 19443,29 w tych kasach.
Zadanie 8.4: Sprzedawca obsługujący najwięcej klientów w największej liczbie sklepów

Pracę nad tym podpunktem zaczynamy od kwerendy pomocniczej, która wypisuje unikalne kombinacje sprzedawca – sklep – miesiąc. Miesiąc wyciągamy z daty funkcją Month([DataTransakcji]), a deduplikację zapewniamy Grupuj według po IdSprzedawcy, IdSklepu i tak zdefiniowanym polu Miesiac. Transakcje z kas samoobsługowych (puste IdSprzedawcy) odrzucamy warunkiem Is Not Null na IdSprzedawcy.
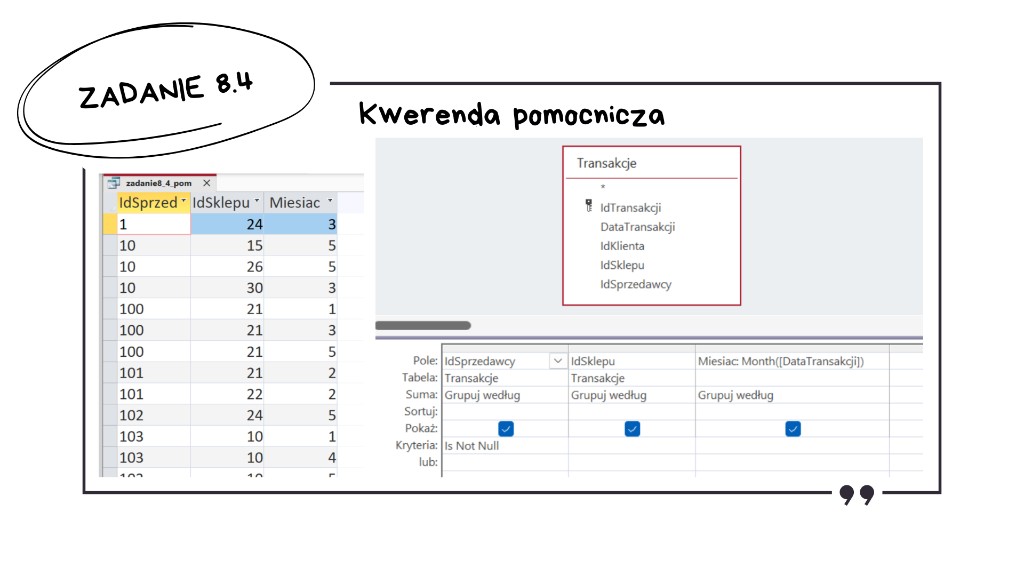
W kwerendzie wynikowej pracujemy już na powyższym zestawieniu (np. zadanie8_4_pom): Grupuj według IdSprzedawcy i Miesiac, a dla IdSklepu stosujemy Policz — dzięki temu dla każdej pary sprzedawca – miesiąc dostajemy liczbę różnych sklepów, w których ten sprzedawca obsłużył klientów. Wynik sortujemy malejąco i odczytujemy pierwszy wiersz.
Zgodnie z poleceniem w odpowiedzi można podać numer lub nazwę miesiąca, więc wartości Miesiac nie trzeba dodatkowo konwertować — wystarczy zapisać tak, jak zwraca to kwerenda.
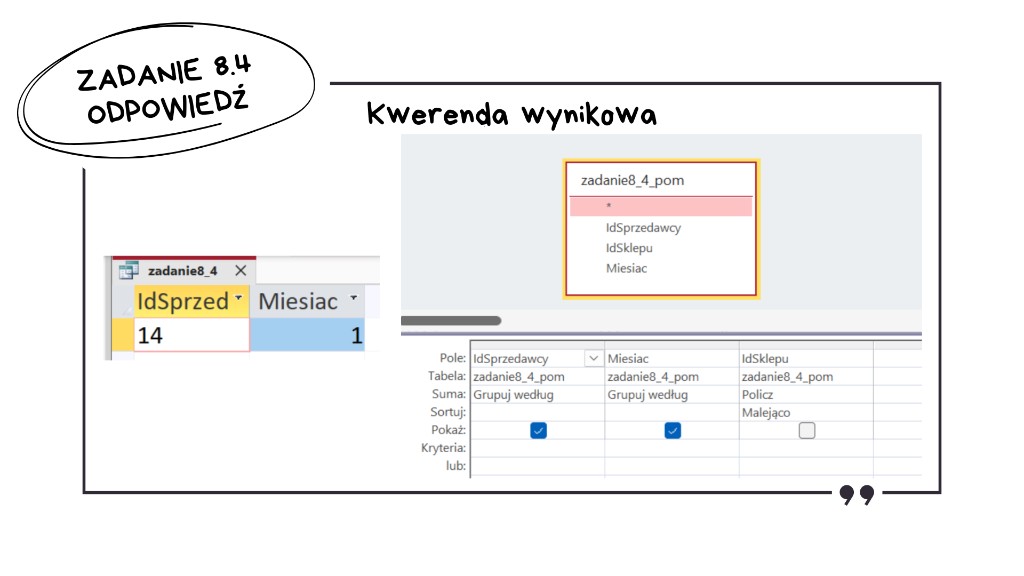
Odpowiedź: IdSprzedawcy, który obsługiwał klientów w największej liczbie różnych sklepów to 14 i był to miesiąc nr 1 (styczeń).
To był ostatni podpunkt rozwiązywany w Microsoft Access, więc po wpisaniu odpowiedzi z 8.1–8.4 możemy zerknąć, jak wygląda przykładowa zawartość pliku wyniki8.txt.

Zadanie 8.5: Zapytanie SQL – nowe tabele Produkty i Kategorie

W ostatnim podpunkcie zadania z baz danych zawsze czeka to samo wyzwanie – napisać zapytanie SQL „na kartce”. W tym roku nie było wyjątku. W zapytaniu potrzebne będą tabele:
- Produkty – do znalezienia fragmentu opisu,
- Kategorie – aby odfiltrować tylko produkty z kategorii 'spozywcze',
- opis_transakcji – aby uwzględnić jedynie te produkty, które zostały zakupione.
Do połączenia tabel użyjemy INNER JOIN – interesują nas tylko rekordy występujące we wszystkich tych tabelach.
Uwaga 1: W LIKE można było również użyć symbolu * jako symbolu wieloznacznego – dozwolona jest zarówno składnia MS Access (symbol *), jak i MySQL (symbol %).
Uwaga 2: Polecenie nie precyzuje wprost, czy produkty w wyniku powinny być unikalne. Dlatego naszym zdaniem akceptowalne są oba podejścia – zarówno wynik z unikalnymi produktami (z użyciem DISTINCT lub grupowania po IdProduktu), jak i wynik z powtórzeniami.
Nowości na maturze z informatyki 2026
Jeżeli chodzi o nowości w tegorocznym arkuszu, to z pewnością można wyróżnić strukturę drzewiastą z zadania 4. Jest to nawiązanie do teorii grafów, która na studiach informatycznych pojawia się praktycznie od pierwszych zajęć, a w zakresie matury z informatyki ogranicza się zaledwie do delikatnego wstępu i bardzo rzadko trafia do arkusza maturalnego. Do rozwiązania zadania formalnie nie była wymagana znajomość teorii grafów, natomiast jej znajomość zdecydowanie ułatwiała zrozumienie i implementację zadania 4.4, które przez wielu uczniów było wskazywane jako najtrudniejsze zadanie tego arkusza – bez rozpisania i zwizualizowania sobie hierarchii pracowników było ono po prostu trudne do ugryzienia.
Drugą zauważalną nowością są dwa podpunkty z symulacją w arkuszu kalkulacyjnym – zadania 7.3 i 7.4. W starych formułach maturalnych (jeszcze sprzed 2015) symulacje bywały całymi, kilkupunktowymi zadaniami, w których pomyłka we wstępie (np. wygenerowanie błędnej osi czasu) przekreślała kolejne podpunkty. Później autorzy arkuszy odeszli od takiego podejścia – do każdego podpunktu dawany był osobny plik wejściowy, więc błąd w jednym zadaniu nie odbierał punktów w pozostałych. Od kilku lat symulacja wraca zwykle w jednym podpunkcie, a w tegorocznym arkuszu mieliśmy aż dwa takie podpunkty z rzędu. Mała nowostka dotyczy też kolejności – zadanie z wykresem (7.1) pojawiło się w arkuszu kalkulacyjnym jako pierwsze, mimo że zazwyczaj było zostawiane na sam koniec albo przedostatni podpunkt.
Wreszcie warto wyróżnić zadanie teoretyczne (zadanie 6) o adresach IPv4 i IPv6. Od wielu lat zadania teoretyczne na maturze przyjmowały formę pytań typu prawda/fałsz albo ABCD, dzięki czemu nawet uczeń zupełnie nieprzygotowany teoretycznie miał szansę trafić ten jeden punkt. W tym roku natomiast trzeba było wpisać dokładną liczbę bitów adresu – a tego nie da się „wystrzelić”. Po prostu trzeba było umieć podać konkretne wartości na pamięć.
Z drugiej strony w tegorocznym arkuszu zabrakło klasycznego „pewniaka” z poprzednich lat, czyli zadania z zamianą iteracji na rekurencję (zazwyczaj jako podpunkt 1.3). W tym roku jego miejsce zajęło zadanie 2.2, w którym zamiast przepisywać algorytm w wersji rekurencyjnej trzeba było po prostu policzyć liczbę przeniesień otrzymanych podczas dodawania pisemnego.
Nie jest to jednak żadna „nowa forma” – warto przy okazji zwrócić uwagę na towarzyszącą temu zadaniu bardzo rozbudowaną uwagę dotyczącą zapisu algorytmu. Zabraniała ona między innymi korzystania z funkcji wbudowanych, tablic i list, a także z dowolnych funkcji konwersji między typem znakowym/napisowym a liczbowym. Widać tu wyraźnie, że autorzy arkuszy konsekwentnie pracują nad tym, aby zdający musiał zapisać algorytm w ściśle określonej, „niskopoziomowej” formie – bez upraszczania go gotowymi narzędziami języka. Zakładamy więc, że to nie tyle nowy wariant zadania, co nowy kierunek: zamiast prostej zamiany iteracji na rekurencję (jak w ostatnich latach) coraz częściej trafi się polecenie napisania algorytmu o mocno zawężonym zestawie dozwolonych konstrukcji.
Standardowo natomiast pojawiło się zadanie z kodami ASCII (zadanie 3), które od wielu lat trafia w niemal każdy arkusz i tym razem również nie należało do trudnych.
Jakie wnioski po maturze z informatyki 2026?
Naszym zdaniem tegoroczny arkusz był delikatnie trudniejszy niż arkusz maturalny 2025, ale nie ze względu na inne ani wyższe umiejętności – wymagany zakres jest praktycznie ten sam. Tym razem treści zadań były po prostu bardziej zawiłe, przez co części uczniów mogło zabraknąć czasu na bezbłędne zrealizowanie wszystkich poleceń. Nie bez znaczenia jest również fakt, że zadań było 8, czyli o jedno więcej niż rok wcześniej – choć to akurat jedynie kosmetyka, bo zadanie z systemami liczbowymi zostało po prostu wydzielone z bloku teorii i potraktowane jako osobne zadanie.
Patrząc na pierwsze cztery zadania widać wyraźnie, że matura coraz mocniej idzie w stronę programowania – jest go więcej i coraz trudniejsze aspekty. W ubiegłym roku programowanie było bardzo łatwe, a więcej problemów sprawiały arkusz kalkulacyjny i baza danych. W tym roku układ jest odwrotny: zauważalnie trudniejsze były właśnie zadania z programowania (szczególnie zadanie 1, zadanie 3 z prefiksem/sufiksem oraz zadanie 4), a arkusz kalkulacyjny i baza danych okazały się stosunkowo proste – poza dwoma podpunktami z symulacją, gdzie najczęściej pojawiały się błędy.
Spośród zadań z programowania największych problemów mogło dostarczyć zadanie 1.3 – wywołania rekurencyjne, których liczba zależała od potęg dwójki (2k) – oraz wspomniane już zadanie 4.4. Z kolei zadanie 2 (dodawanie pisemne) było wręcz szokująco proste, podobnie jak początek zadania 3 o parach słów. W zadaniu 4.4 bez rozrysowania i zwizualizowania drzewa zależności uczniowi naprawdę trudno było udzielić poprawnej odpowiedzi (dlatego w naszym omówieniu konsekwentnie rysujemy schemat hierarchii pracowników). Dodatkowo w podpunktach od 4.2 do 4.4 łatwo było źle zinterpretować plik wejściowy (numer wiersza vs wartość w wierszu) – a jedna taka pomyłka potrafiła pokrzyżować odpowiedzi do całego zadania 4.
Zadanie z arkusza kalkulacyjnego – poza wspomnianymi podpunktami symulacji – nie sprawiało większych problemów. Podobnie zadanie z bazy danych: bardzo typowe, szybkie „przeklikanie” danych, bez konieczności budowania rozbudowanej struktury kilku pomocniczych kwerend. Pojawiło się również standardowe zadanie z niepasującymi danymi (podpunkt 8.2), ale i ono w tegorocznym arkuszu należało do klasycznych, bez nieoczekiwanych pułapek. Również SQL w ostatnim podpunkcie – z dwiema dodatkowymi tabelami – nie odbiegał poziomem od standardu poprzednich lat (czy są to dwie, czy jedna dodatkowa tabela, w praktyce sprowadza się do tego samego). Krótko mówiąc: matura 2026 to nieco trudniejsze programowanie oraz bardziej zawiłe treści przy zasadniczo tym samym poziomie wymaganych umiejętności co lata wcześniej.
Komentarze
- @zielonazaba191 czerwca 2026 12:10❤️ 1
pozdrawiam wszystkich ktorzy za rok beda to powtarzac na ostatnia chwile

